Regex (정규표현식) vs Text Replace (문자열 치환) 개념과 구문
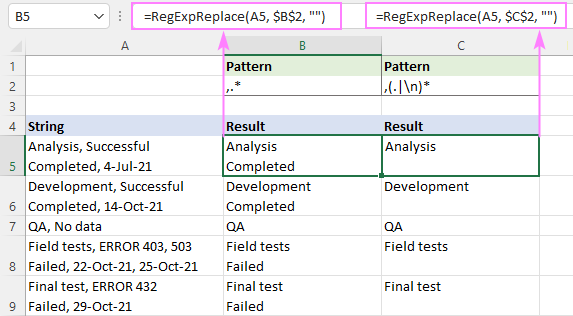
(?P<logType>.*?)와 replace(".*", "\1") 방식의 치환은 텍스트 처리와 정규 표현식(regex)에 있어서 주로 사용되는 두 가지 다른 접근 방식입니다. 이 두 방식을 이해하기 위해서는 먼저 정규 표현식의 기본적인 개념과 구문에 대한 이해가 필요합니다.
(?P<logType>.*?) 설명
- 구문:
(?P<name>pattern) - 용도: 이 구문은 정규 표현식에서 그룹화(grouping)와 함께 이름을 부여하는 데 사용됩니다. 여기서
name은 그룹에 부여할 이름이고,pattern은 해당 그룹이 매칭할 패턴입니다. - 활용: Python의
re모듈 같은 정규 표현식을 지원하는 언어나 라이브러리에서 사용됩니다. 이름이 부여된 그룹은 매칭된 텍스트를 더 쉽게 참조하고 사용할 수 있게 해 줍니다. 예를 들어, 로그 파일에서 특정 로그 유형을 추출하고 싶을 때 유용합니다.
replace(".*", "\1") 설명
- 구문: 텍스트의
replace메서드와 정규 표현식의 교체 기능을 결합한 방식입니다. 여기서.*은 모든 문자에 대응되는 패턴이며,\1은 첫 번째 괄호로 그룹화된 부분의 참조입니다. - 용도: 이 방식은 주로 텍스트 내의 특정 패턴을 찾아 다른 텍스트로 교체하는 데 사용됩니다.
- 활용: 문자열 처리에 널리 사용되며, 특정 형식의 데이터를 다른 형식으로 변환하거나, 데이터 정제 작업에 유용하게 쓰입니다.
차이점과 활용
- 차이점:
(?P<logType>.*?)는 정규 표현식 내에서 특정 패턴을 매칭하는 그룹에 이름을 부여하는 방식입니다. 반면,replace(".*", "\1")는 특정 패턴을 찾아 그 패턴과 매칭되는 텍스트를 다른 텍스트로 교체하는 작업에 초점을 맞춥니다. 전자는 패턴 매칭과 데이터 추출에, 후자는 데이터의 변환과 정제에 더 적합합니다. - 유형 및 용도
(?P<logType>.*?)는 데이터 분석, 로그 파일 처리, 특정 형식의 텍스트에서 필요한 정보 추출 등에 사용됩니다.replace(".*", "\1")는 데이터 정제, 텍스트 포맷 변경, 사용자 입력의 정규화 같은 상황에서 사용됩니다.
정리하자면, 두 방식은 정규 표현식을 활용한 텍스트 처리의 다양한 측면을 다루며, 각각의 특정 상황과 요구 사항에 따라 선택하여 사용됩니다.
아래에서는 Python의 re 모듈을 사용한 예제 코드를 통해 (?P<logType>.*?)와 replace(".*", "\1") 각각의 사용 방법을 설명합니다.
(?P<logType>.*?) 사용 예제
이 예제에서는 로그 파일에서 다양한 로그 유형을 추출하는 상황을 가정해 봅시다. 로그 유형을 그룹화하고, 각 로그 유형의 이름을 지정하여 추출하는 방법을 보여줍니다.
import re
# 로그 예제
log_entries = [
"ERROR: File not found.",
"WARNING: An unknown error occurred.",
"INFO: Processing completed."
]
# 로그 유형을 추출하기 위한 정규 표현식
log_pattern = re.compile(r'(?P<logType>ERROR|WARNING|INFO): (?P<message>.*)')
for entry in log_entries:
match = log_pattern.match(entry)
if match:
print(f"Log Type: {match.group('logType')}, Message: {match.group('message')}")이 코드는 각 로그 엔트리에서 "ERROR", "WARNING", "INFO" 중 하나를 logType으로 추출하고, 그에 따른 메시지를 message로 분류해 출력합니다.
replace(".*", "\1") 사용 예제
이 방법은 실제로 Python에서는 조금 다르게 적용됩니다. Python의 re.sub() 함수를 사용하여 유사한 작업을 수행할 수 있습니다. replace 메서드와 혼동하지 않도록 주의하세요. 여기서는 간단한 텍스트 패턴을 다른 텍스트로 교체하는 예를 들어 보겠습니다.
import re
# 원본 문자열
original_text = "The quick brown fox jumps over the lazy dog."
# 'quick'을 'slow', 'brown'을 'red', 'fox'을 'turtle'로 교체
modified_text = re.sub(r'The (quick) (brown) (fox)', r'The slow red turtle', original_text)
print(modified_text)이 코드는 "The quick brown fox" 패턴을 찾아 "The slow red turtle"로 교체합니다. 정규 표현식 내에서 괄호는 그룹을 의미하지만, 이 예제에서는 단순히 전체 패턴을 교체하는 방식을 보여줍니다. \1, \2 같은 참조는 교체할 문자열 내에서 그룹화된 부분을 참조할 때 사용됩니다.
위의 예제들은 각각의 기능을 보여주기 위한 것이며, 실제 사용 시에는 각 상황에 맞게 코드를 조정해야 합니다.
정규 표현식과 문자열 처리에서 사용되는 다양한 치환 유형과 기술에 대한 방법들은 데이터 가공, 검증, 분석 등 여러 분야에서 유용하게 쓰입니다.
1. 기본 그룹 참조(\1, \2, ...)
- 설명: 정규 표현식에서 괄호
()를 사용하여 그룹화된 패턴을 참조합니다.\1,\2등은 첫 번째, 두 번째 그룹화된 패턴을 참조하는 방법입니다. - 활용: 문자열의 특정 부분을 재배치하거나, 중복되는 문자열을 찾아 처리할 때 유용합니다.
2. 이름이 지정된 그룹 참조((?P=name))
- 설명:
(?P<name>pattern)을 사용하여 정의된 이름이 지정된 그룹을 나중에(?P=name)을 통해 참조합니다. - 활용: 복잡한 정규 표현식 내에서 특정 패턴을 명확히 식별하고 재사용할 때 유용합니다.
3. 전방 탐색(lookahead) 및 후방 탐색(lookbehind)
- 설명: 전방 탐색(
(?=pattern))과 후방 탐색((?<=pattern))은 특정 패턴 앞이나 뒤에 오는 텍스트를 찾는데 사용됩니다. 이들은 패턴에 매칭되는 부분을 소비하지 않습니다(즉, 결과에 포함시키지 않음). - 활용: 특정 조건을 만족하는 문자열을 찾되, 그 조건은 결과에 포함시키고 싶지 않을 때 사용합니다.
4. 부정형 전방 탐색(negative lookahead) 및 부정형 후방 탐색(negative lookbehind)
- 설명: 부정형 전방 탐색(
(?!pattern))과 부정형 후방 탐색((?<!pattern))은 특정 패턴이 아닌 경우에만 일치시킵니다. - 활용: 특정 문자열을 제외한 경우에만 매칭하고 싶을 때 사용합니다.
5. 비탐욕적 일치(Non-greedy matching)
- 설명:
*?,+?,??,{n,m}?와 같은 문법을 사용하여 가능한 가장 짧은 문자열에 일치시키려고 합니다. 기본적으로*,+,?,{n,m}는 탐욕적으로 동작하여 가능한 가장 긴 문자열에 일치합니다. - 활용: 특정 태그나 괄호로 둘러싸인 최소 문자열을 추출할 때 유용합니다.
6. 문자열의 replace() 메서드
- 설명: Python 등의 프로그래밍 언어에서 제공하는
replace(old, new[, count])메서드를 사용하여 문자열 내에서 특정 패턴이나 문자열을 새로운 것으로 치환합니다. - 활용: 정규 표현식 없이 단순 문자열 교체가 필요할 때 사용합니다.
7. 정규 표현식의 re.sub() 함수
- 설명:
re.sub(pattern, repl, string, count=0, flags=0)함수는 정규 표현식에 매칭되는 부분을 다른 문자열로 교체합니다. - 활용: 복잡한 패턴에 기반한 문자열 교체가 필요할 때 사용합니다.
8. 정규 표현식의 re.findall() 함수
- 설명:
re.findall(pattern, string, flags=0)함수는 문자열 내에서 정규 표현식에 매칭되는 모든 부분을 찾아 리스트로 반환합니다. - 활용: 특정 패턴에 해당하는 모든 데이터를 추출할 때 유용합니다. 예를 들어, 이메일 주소나 URL 등을 텍스트에서 찾아내는 데 사용될 수 있습니다.
9. 정규 표현식의 re.finditer() 함수
- 설명:
re.finditer(pattern, string, flags=0)함수는findall과 유사하지만, 모든 매치에 대해 iterator를 반환합니다. 각 매치는Match객체입니다. - 활용: 대량의 데이터를 처리할 때 메모리를 절약하면서 매칭된 결과를 순회하고자 할 때 유용합니다.
10. 정규 표현식의 re.match()와 re.search() 함수
- 설명:
re.match(pattern, string, flags=0)함수는 문자열의 시작에서 패턴과 일치하는지 확인합니다.re.search(pattern, string, flags=0)는 문자열 전체에서 첫 번째로 패턴과 일치하는 부분을 찾습니다. - 활용:
match는 문자열의 시작부터 패턴이 일치하는지 검사할 때,search는 문자열 어디에나 패턴이 존재하는지 찾고자 할 때 사용됩니다.
이러한 다양한 방법과 기술들은 정규 표현식과 문자열 처리의 강력함을 보여줍니다. 각각의 방법은 특정 상황에 맞게 선택하여 사용할 수 있으며, 종종 함께 사용되어 복잡한 텍스트 처리 작업을 수행합니다.
정규 표현식과 문자열 처리 기술들은 데이터를 처리하고 분석하는 데 있어서 매우 강력한 도구입니다. 위에서 설명한 방법들은 상황에 따라 서로 다른 방식으로 조합하거나 단독으로 사용될 수 있으며, 텍스트 데이터를 가공하고 원하는 정보를 추출하는 데 큰 도움을 줍니다. 프로그래밍 언어나 라이브러리에 따라 구체적인 구현 방법이나 함수명은 다를 수 있으므로, 사용하는 언어의 문서를 참조하여 해당 기능을 최대한 활용하는 것이 중요합니다.