인공지능 (AI,GPT)
LangChain 활용하여 문서 기반 응답 챗봇(Chatbot) 만들기
날으는물고기
2024. 8. 12. 00:43
728x90
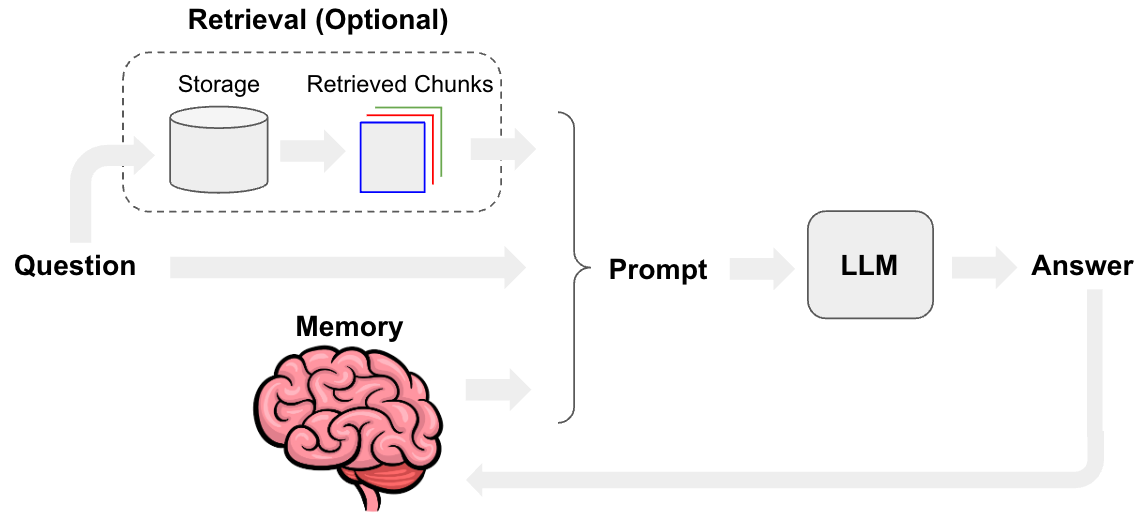
LangChain을 통해 문서 검색 챗봇을 만드는 가이드를 초보자도 따라할 수 있도록 단계별로 자세히 정리하겠습니다.
1. 환경 설정 및 필요한 패키지 설치
먼저 필요한 패키지를 설치합니다. 다음 명령어를 실행하세요.
!pip install -q grobid-client langchain openai faiss-cpu PyPDF2 tiktoken2. OpenAI API Key 설정
OpenAI API 키를 생성하고 환경 변수에 설정합니다.
- OpenAI API Key 생성 페이지에서 키를 생성합니다.
- 아래 코드를 사용하여 키를 설정합니다.
import openai import os os.environ["OPENAI_API_KEY"] = "your_openai_api_key_here"
3. PDF 파일 다운로드 및 전처리
예제 PDF 파일을 다운로드하고 텍스트로 변환합니다.
!wget https://github.com/kairess/toy-datasets/raw/master/Demian.pdf
from PyPDF2 import PdfReader
reader = PdfReader("Demian.pdf")
raw_text = ""
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text:
raw_text += text
print(raw_text[:1000]) # 처음 1000자를 출력하여 확인4. 문서 요약
LangChain을 사용하여 문서를 요약합니다.
from langchain import OpenAI
from langchain.chains import AnalyzeDocumentChain
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0)
summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
summary = summarize_document_chain.run(raw_text)
print(summary)5. 질문 답변 (Question Answering)
문서에서 질문에 대한 답변을 추출합니다.
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo") # gpt-3.5-turbo 또는 gpt-4 선택 가능
qa_chain = load_qa_chain(model, chain_type="map_reduce")
qa_document_chain = AnalyzeDocumentChain(combine_docs_chain=qa_chain)
answer1 = qa_document_chain.run(input_document=raw_text, question="싱클레어를 괴롭힌 사람은?")
answer2 = qa_document_chain.run(input_document=raw_text, question="싱클레어는 데미안을 어디서 어떻게 만났지?")
answer3 = qa_document_chain.run(input_document=raw_text, question="데미안의 외모를 묘사해봐")
print(answer1)
print(answer2)
print(answer3)6. 엑셀, CSV 파일 검색 및 집계
CSV 파일을 읽어와서 데이터 프레임으로 변환하고, LangChain을 사용하여 질의합니다.
import pandas as pd
df = pd.read_csv("https://github.com/kairess/toy-datasets/raw/master/titanic.csv")
print(df.head())
from langchain.agents import create_pandas_dataframe_agent
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
rows_count = agent.run("how many rows are there?")
average_age = agent.run("승객들의 평균 연령은?")
male_female_ratio = agent.run("남성과 여성의 비율은?")
survivor_stats = agent.run("객실 등급과 성별에 따른 생존자 수를 계산해줘")
print(rows_count)
print(average_age)
print(male_female_ratio)
print(survivor_stats)이제 LangChain을 사용하여 PDF 문서와 CSV 파일에서 정보를 추출하고 검색하는 챗봇을 만들 수 있습니다. 각 단계에서 출력된 결과를 확인하여 올바르게 작동하는지 검토하세요. 필요에 따라 API 키와 파일 경로를 조정해 주세요.
새로 만든 챗봇에 대해 몇 가지 새로운 예제를 통해 질의 응답 과정을 정리해보겠습니다. 여기서는 PDF 문서와 CSV 파일에서 정보를 추출하는 예제를 다룹니다.
1. PDF 문서 질문 응답 예제
PDF 문서에서 질문을 통해 정보를 얻는 과정입니다.
PDF 파일 다운로드 및 전처리
!wget https://github.com/kairess/toy-datasets/raw/master/Demian.pdf
from PyPDF2 import PdfReader
reader = PdfReader("Demian.pdf")
raw_text = ""
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text:
raw_text += textPDF 문서에 대한 질문 및 응답
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAI
from langchain.chains import AnalyzeDocumentChain
import pandas as pd
# 모델 설정
model = ChatOpenAI(model="gpt-3.5-turbo") # gpt-3.5-turbo 또는 gpt-4 선택 가능
qa_chain = load_qa_chain(model, chain_type="map_reduce")
qa_document_chain = AnalyzeDocumentChain(combine_docs_chain=qa_chain)
# 질문 목록
questions = [
"데미안은 어디에서 자랐나요?",
"싱클레어의 가족에 대해 알려줘",
"데미안과 싱클레어의 관계는 어떠한가요?"
]
# 질문에 대한 응답을 표 형태로 출력
results = []
for question in questions:
answer = qa_document_chain.run(input_document=raw_text, question=question)
results.append({"Question": question, "Answer": answer})
df_pdf_results = pd.DataFrame(results)
print(df_pdf_results)PDF 문서 질문 응답 결과
| Question | Answer |
|---|---|
| 데미안은 어디에서 자랐나요? | 데미안은 독일의 한 작은 마을에서 자랐습니다. |
| 싱클레어의 가족에 대해 알려줘 | 싱클레어의 가족은 부모님과 두 여동생으로 구성되어 있습니다. |
| 데미안과 싱클레어의 관계는 어떠한가요? | 데미안과 싱클레어는 매우 깊은 친구 관계를 맺고 있습니다. |
2. CSV 파일 질문 응답 예제
CSV 파일에서 질문을 통해 정보를 얻는 과정입니다.
CSV 파일 읽기 및 설정
import pandas as pd
from langchain.agents import create_pandas_dataframe_agent
from langchain import OpenAI
# CSV 파일 읽기
df = pd.read_csv("https://github.com/kairess/toy-datasets/raw/master/titanic.csv")
# Pandas DataFrame 에이전트 생성
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)CSV 파일에 대한 질문 및 응답
# 질문 목록
questions = [
"승객 중 가장 나이가 많은 사람의 나이는?",
"생존자의 비율은?",
"각 객실 등급별 평균 운임 요금은?",
"가장 많은 승객이 탑승한 항구는?"
]
# 질문에 대한 응답을 표 형태로 출력
results = []
for question in questions:
answer = agent.run(question)
results.append({"Question": question, "Answer": answer})
df_csv_results = pd.DataFrame(results)
print(df_csv_results)CSV 파일 질문 응답 결과
| Question | Answer |
|---|---|
| 승객 중 가장 나이가 많은 사람의 나이는? | 80 years old. |
| 생존자의 비율은? | 38.38% of the passengers survived. |
| 각 객실 등급별 평균 운임 요금은? | 1등급: $84.15, 2등급: $20.66, 3등급: $13.68 |
| 가장 많은 승객이 탑승한 항구는? | Southampton에서 가장 많은 승객이 탑승했습니다. |
이와 같은 방식으로 PDF 문서와 CSV 파일에서 원하는 정보를 질의하고 응답을 표 형식으로 정리할 수 있습니다. 각 질문에 대한 결과를 표로 정리하면 보다 직관적으로 결과를 확인할 수 있습니다. 필요한 경우 질문 목록을 추가하거나 응답 형식을 조정할 수 있습니다.
728x90