
벡터 DB를 로컬 환경에서 Docker를 사용하여 설정하고 데이터를 쿼리하는 과정을 단계별로 설명하겠습니다.
단계 1: Chroma DB GitHub 저장소 복제
Chroma DB를 로컬 머신으로 가져오기 위해 GitHub 저장소를 복제합니다. 이 저장소는 Chroma DB의 소스 코드를 포함하고 있습니다. 아래 명령어를 사용하여 저장소를 복제합니다.
git clone https://github.com/chroma-core/chroma이 명령어를 실행하면 현재 작업 디렉토리에 "chroma" 디렉토리가 생성되고 그 안에 Chroma DB 소스 코드가 복제됩니다.
단계 2: Docker를 사용하여 Chroma 실행
Chroma DB를 Docker 컨테이너로 실행합니다. Docker를 사용하면 Chroma DB를 가상 환경에서 실행할 수 있습니다. 복제한 "chroma" 디렉토리로 이동한 다음 아래 명령어를 사용합니다.
cd chroma
docker-compose up -d --builddocker-compose: Docker 컴포즈는 여러 개의 도커 컨테이너를 정의하고 실행하기 위한 도구입니다.up -d: 이 플래그를 사용하면 컨테이너가 백그라운드에서 실행됩니다.--build: 이 플래그를 사용하면 Docker 이미지를 빌드할 수 있습니다.
이 명령어를 실행하면 Docker가 Chroma DB 컨테이너를 빌드하고 실행합니다. Chroma DB는 포트 8000에서 실행됩니다.

단계 3: Chroma DB 서버 접속
Chroma DB 서버에 Python을 사용하여 연결하려면 chromadb-client 패키지를 설치해야 합니다. 이 패키지를 사용하여 Chroma DB와 통신합니다.
pip install chromadb-clientpip: Python 패키지 관리자입니다. 패키지 설치와 관리에 사용됩니다.
chromadb-client를 설치하고 나면 Python 스크립트에서 Chroma DB 서버와 통신할 수 있습니다. 다음은 Chroma DB 서버에 연결하는 예제 코드입니다.
import chromadb
chroma_client = chromadb.HttpClient(host="localhost", port=8000)
print(chroma_client.list_collections())chromadb.HttpClient: Chroma DB와 통신하기 위한 HTTP 클라이언트 객체를 생성합니다.host="localhost": Chroma DB 서버의 호스트 주소입니다. 로컬에서 실행 중인 경우 "localhost"로 설정합니다.port=8000: Chroma DB 서버가 노출한 포트 번호입니다. 일반적으로 8000 포트를 사용합니다.
이로써 Chroma DB 서버에 연결되었습니다.

단계 4: Chroma 컬렉션 생성
Chroma DB에서 데이터를 저장하기 위해 컬렉션을 생성해야 합니다. 컬렉션은 데이터를 그룹화하고 저장하는 역할을 합니다. 아래 코드 예제에서는 "my_test_collection"이라는 이름의 새로운 컬렉션을 생성합니다.
collection = chroma_client.create_collection(name="my_test_collection")chroma_client.create_collection(): Chroma DB에 새로운 컬렉션을 생성하는 메서드입니다.name매개변수를 사용하여 컬렉션의 이름을 지정합니다.
list_collections() 함수를 사용하면 새로 생성된 컬렉션이 반환됩니다.
[Collection(name=my_test_collection)]
단계 5: 컬렉션 데이터 보기
컬렉션에 저장된 데이터를 확인하려면 peek() 함수를 사용합니다. 이 함수는 컬렉션에 저장된 데이터를 반환합니다.
collection = chroma_client.get_collection("my_test_collection")
collection.peek()chroma_client.get_collection(): 컬렉션에 대한 참조를 얻는 메서드입니다. "my_test_collection"은 컬렉션의 이름입니다.collection.peek(): 컬렉션에 저장된 데이터를 표시합니다.
지속형 레코드에는 id , embedding , Metadata 및 document 의 4가지 속성이 있습니다.
- id: 레코드의 고유 식별자입니다.
- embedding: 문서의 삽입 데이터를 포함합니다.
- 메타데이터: 문서와 함께 유지하려는 메타데이터가 포함되어 있습니다.
- document: 컬렉션에 저장하려는 데이터 청크입니다.
{'ids': [], 'embeddings': [], 'metadatas': [], 'documents': []}컬렉션이 비어 있으므로 모든 속성에 대해 빈 배열을 얻습니다.
단계 6: 데이터 컬렉션에 삽입
데이터를 컬렉션에 삽입하기 위해 데이터를 작은 조각으로 분할하고 컬렉션에 추가해야 합니다. 아래 코드 예제에서는 데이터를 분할하고 컬렉션에 추가하는 함수를 보여줍니다.
import chromadb
import uuid
from langchain.text_splitter import RecursiveCharacterTextSplitter
from chromadb.utils import embedding_functions
def insert(content):
client = chromadb.HttpClient(host="localhost", port=8000)
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=OPENAI_API_KEY,
model_name="text-embedding-ada-002"
)
collection = client.get_collection(name="my_test_collection", embedding_function=openai_ef)
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n"], chunk_size=200, chunk_overlap=30)
docs = text_splitter.create_documents([content])
for doc in docs:
uuid_val = uuid.uuid1()
print("Inserted documents for ", uuid_val)
collection.add(ids=[str(uuid_val)], documents=doc.page_content)insert() 함수: 데이터를 작은 조각으로 나누고 컬렉션에 추가하는 함수입니다.openai_ef = embedding_functions.OpenAIEmbeddingFunction(): OpenAI Embedding 함수를 사용하여 데이터를 임베딩하고 Chroma DB에 추가합니다. API 키와 모델 이름을 설정해야 합니다.

{'ids': ['ca0ede6a-328c-11ee-9349-4cd577cb7c58',
'cac5ab41-328c-11ee-bb75-4cd577cb7c58'],
'embeddings': [[0.0011678459122776985,
-0.008723867125809193,
-0.01643379032611847,
.
.
-0.018491532653570175,
0.024459557607769966,
...]],
'metadatas': [None, None],
'documents': ['The story centres on Alice, a young girl who falls asleep in a meadow and dreams that she follows the White Rabbit down a rabbit hole. She has many wondrous, often bizarre adventures with thoroughly illogical and very strange creatures, often changing size unexpectedly (she grows as tall as a house and shrinks to 3 inches [7 cm]). She encounters the hookah-smoking Caterpillar, the Duchess (with a baby that becomes a pig), and the Cheshire Cat, and she attends a strange endless tea party with the Mad Hatter and the March Hare. She plays a game of croquet with an unmanageable flamingo for a croquet mallet and uncooperative hedgehogs for croquet balls while the Queen calls for the execution of almost everyone present. Later, at the Queen’s behest, the Gryphon takes Alice to meet the sobbing Mock Turtle, who describes his education in such subjects as Ambition, Distraction, Uglification, and Derision. ',
'\nAlice is then called as a witness in the trial of the Knave of Hearts, who is accused of having stolen the Queen’s tarts. However, when the Queen demands that Alice be beheaded, Alice realizes that the characters are only a pack of cards, and she then awakens from her dream.']}
단계 7: 데이터 쿼리
데이터를 검색하려면 Chroma DB와 Langchain을 사용합니다.
pip install chromadbChroma DB 패키지를 설치하고 데이터를 쿼리하기 위한 함수를 작성합니다.
import chromadb
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
def queryDB(query):
client = chromadb.HttpClient(host="localhost", port=8000)
embedding_function = OpenAIEmbeddings()
db4 = Chroma(client=client, collection_name="my_test_collection", embedding_function=embedding_function)
docs = db4.similarity_search(query)
return docsqueryDB() 함수: Chroma DB에서 데이터를 검색하는 함수입니다.query는 검색할 쿼리 문자열을 나타냅니다.db4.similarity_search(): 유사성 검색 함수를 사용하여 데이터를 검색합니다. 이 함수는 쿼리와 가장 유사한 데이터를 반환합니다.
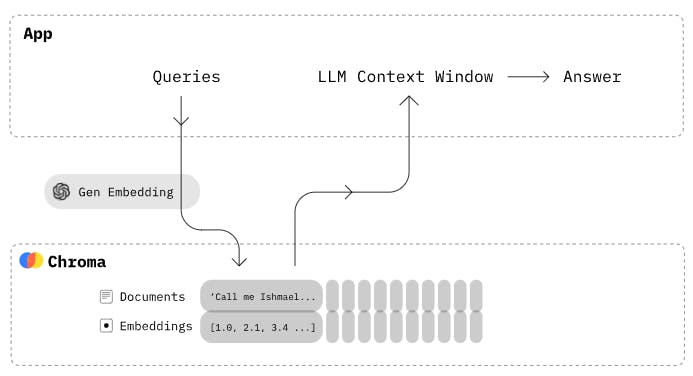
이제 queryDB 함수를 사용하여 DB를 쿼리해 보겠습니다.

"Alice the young girl" 문장으로 DB를 쿼리하려고 시도한 스크린샷이며, 이 텍스트와 가장 가까운 일치 항목을 반환했습니다.
단계 8: 개인 데이터 추가 및 쿼리
개인 데이터를 Chroma DB에 추가하고 쿼리하려면 다음 단계를 따릅니다.
1. 웹 사이트에서 데이터를 스크래핑하는 함수를 작성합니다. 이 함수는 웹 사이트에서 정보를 가져오는 역할을 합니다.
from langchain.document_loaders import SeleniumURLLoader
from bs4 import BeautifulSoup
def scrape(url):
urls = [url]
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
if data is not None and len(data) > 0:
soup = BeautifulSoup(data[0].page_content, "html.parser")
text = soup.get_text()
return text
return ''2. 스크래핑한 데이터를 Chroma DB에 추가하는 함수를 작성합니다. 데이터를 작은 조각으로 나누고 컬렉션에 추가합니다.
import chromadb
import uuid
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from chromadb.utils import embedding_functions
def addDataToDB(content):
client = chromadb.HttpClient(host="localhost", port=8000)
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=OPENAI_API_KEY,
model_name="text-embedding-ada-002"
)
collection = client.get_collection(name="my_collection", embedding_function=openai_ef)
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n"], chunk_size=500, chunk_overlap=50)
docs = text_splitter.create_documents([content])
for doc in docs:
uuid_val = uuid.uuid1()
print("Inserted documents for ", uuid_val)
collection.add(ids=[str(uuid_val)], documents=doc.page_content)3. 데이터를 쿼리하는 함수를 작성합니다. 이 함수는 입력된 쿼리와 일치하는 데이터를 검색합니다.
import chromadb
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
def queryDB(query):
client = chromadb.HttpClient(host="localhost", port=8000)
embedding_function = OpenAIEmbeddings()
db4 = Chroma(client=client, collection_name="my_collection", embedding_function=embedding_function)
docs = db4.similarity_search(query)
return docs이제 개인 데이터를 Chroma DB에 추가하고 해당 데이터를 쿼리할 수 있게 되었습니다.

이러한 단계를 따라 Chroma DB를 로컬 환경에서 설정하고 데이터를 쿼리할 수 있을 것입니다.
그러나 주의해야 할 점은 OPENAI_API_KEY와 같은 중요 정보를 안전하게 관리해야 합니다.




댓글