Docker 컨테이너 내에서 OWASP ZAP 프록시를 실행하고, 각 사이트를 점검한 후 리포트를 생성하는 Python 코드를 작성해보겠습니다. 이를 위해서는 zap-cli 라이브러리를 사용할 것입니다. 코드는 사이트 목록을 반복하면서 ZAP을 사용하여 각 사이트를 점검하고 리포트를 생성할 것입니다.
먼저, zap-cli 라이브러리를 설치합니다.
pip install zap-cli다음은 Python 코드의 예시입니다.
import subprocess
import time
# 대상 사이트 목록
target_sites = [
"http://site1.com",
"http://site2.com",
"http://site3.com",
# 필요한 만큼 사이트를 추가하세요.
]
# Docker 컨테이너 실행 (ZAP 프록시)
docker_command = [
"docker", "run", "--name", "zap-container",
"-u", "zap", "-p", "8080:8080",
"-d", "owasp/zap2docker-stable", "zap.sh", "-daemon", "-host", "0.0.0.0", "-port", "8080"
]
subprocess.run(docker_command)
# 컨테이너가 실행되기 위한 시간을 줍니다 (조정 필요)
time.sleep(10)
# 대상 사이트를 ZAP 프록시를 통해 스캔하고 리포트 생성
for site_url in target_sites:
# ZAP 프록시를 통해 대상 사이트 접근
zap_command = [
"docker", "run", "--rm",
"--network", "host", # Docker 컨테이너가 호스트 네트워크와 통신할 수 있도록 설정
"owasp/zap2docker-stable", "zap-cli", "quick-scan",
"-t", site_url,
]
subprocess.run(zap_command)
# 리포트 생성
report_command = [
"docker", "run", "--rm",
"--network", "host",
"-v", "/path/to/report/directory:/zap/wrk",
"owasp/zap2docker-stable", "zap-cli", "report",
"-o", f"/zap/wrk/{site_url.replace('://', '_').replace('/', '_')}.html",
"-f", "html",
]
subprocess.run(report_command)
# Docker 컨테이너 종료
subprocess.run(["docker", "stop", "zap-container"])위 코드에서는 target_sites 리스트에 대상 웹 사이트 URL을 추가하고, 각 사이트를 순차적으로 ZAP 프록시를 통해 스캔한 후 리포트를 생성합니다. 리포트는 /path/to/report/directory 디렉토리에 저장됩니다. 코드를 실행하기 전에 /path/to/report/directory를 실제 리포트를 저장할 디렉토리로 변경하세요.
또한, Docker 컨테이너가 실행되기까지의 시간을 고려하여 time.sleep()의 대기 시간을 조정할 수 있습니다.
OWASP ZAP(Zed Attack Proxy)를 유지하면서 웹사이트 취약점을 자동으로 점검하고 결과 리포팅을 수집하기 위해서는 ZAP API와 스크립트를 사용하여 자동화할 수 있습니다. 대상 사이트 목록을 정의하고 해당 사이트를 주기적으로 반복해서 점검하는 방법을 보여줍니다.
먼저, 필요한 Python 패키지를 설치합니다.
pip install python-owasp-zap-v2.4그런 다음, 아래의 Python 스크립트를 사용하여 ZAP를 자동화할 수 있습니다.
import time
from datetime import datetime
from zapv2 import ZAPv2
# ZAP Docker 서비스 URL 설정
zap_url = "http://your-docker-host-ip:8080" # ZAP Docker 서비스 URL
# 대상 웹사이트 설정
target_sites = [
"https://example.com", # 추가 대상 사이트
"https://example2.com",
]
# ZAP 프록시 시작
zap = ZAPv2(proxies={'http': zap_url, 'https': zap_url})
# 현재 날짜 가져오기 (년월일 시분초 형식)
current_date = datetime.now().strftime("%Y%m%d%H%M%S")
# 대상 사이트 목록을 반복해서 점검
for site in target_sites:
print(f"Scanning {site}...")
# ZAP에서 사이트 추가
zap.urlopen(site)
# Active 스캔 시작
scan_id = zap.ascan.scan(site)
# 스캔이 완료될 때까지 대기
while int(zap.ascan.status(scan_id)) < 100:
print(f"Scan progress: {zap.ascan.status(scan_id)}%")
time.sleep(5) # 5초 대기
print(f"Scan for {site} complete.")
# HTML 리포팅 생성 및 저장
html_report = zap.core.htmlreport()
html_report_filename = f"zap_report_{site.replace('http://', '').replace('https://', '')}_{current_date}.html"
with open(html_report_filename, "w") as f:
f.write(html_report)
# JSON 리포팅 생성 및 저장
json_report = zap.core.jsonreport()
json_report_filename = f"zap_report_{site.replace('http://', '').replace('https://', '')}_{current_date}.json"
with open(json_report_filename, "w") as f:
f.write(json_report)
# 현재 사이트의 진단이 완료되었으므로 ZAP 세션을 종료
zap.core.new_session()
# ZAP 종료
zap.core.shutdown()위의 코드에서 target_sites 리스트에 대상 사이트 목록을 추가하고, ZAP 프록시 주소를 설정합니다. 코드는 각 사이트에 대해 ZAP를 시작하고 Active 스캔을 수행한 후, 스캔이 완료될 때까지 대기하고 결과 리포트를 생성합니다. 결과 리포트는 각 사이트의 이름으로 저장됩니다.
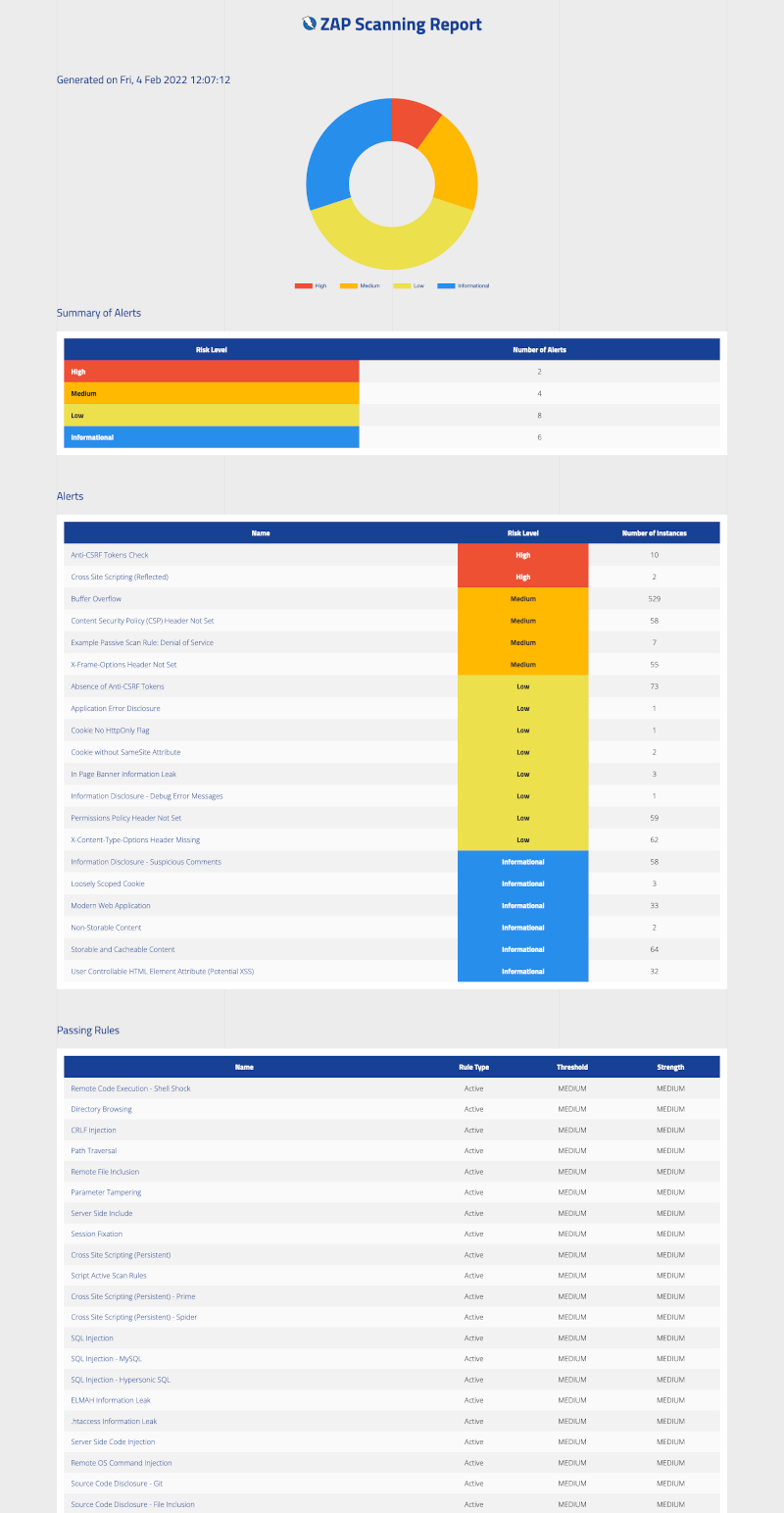
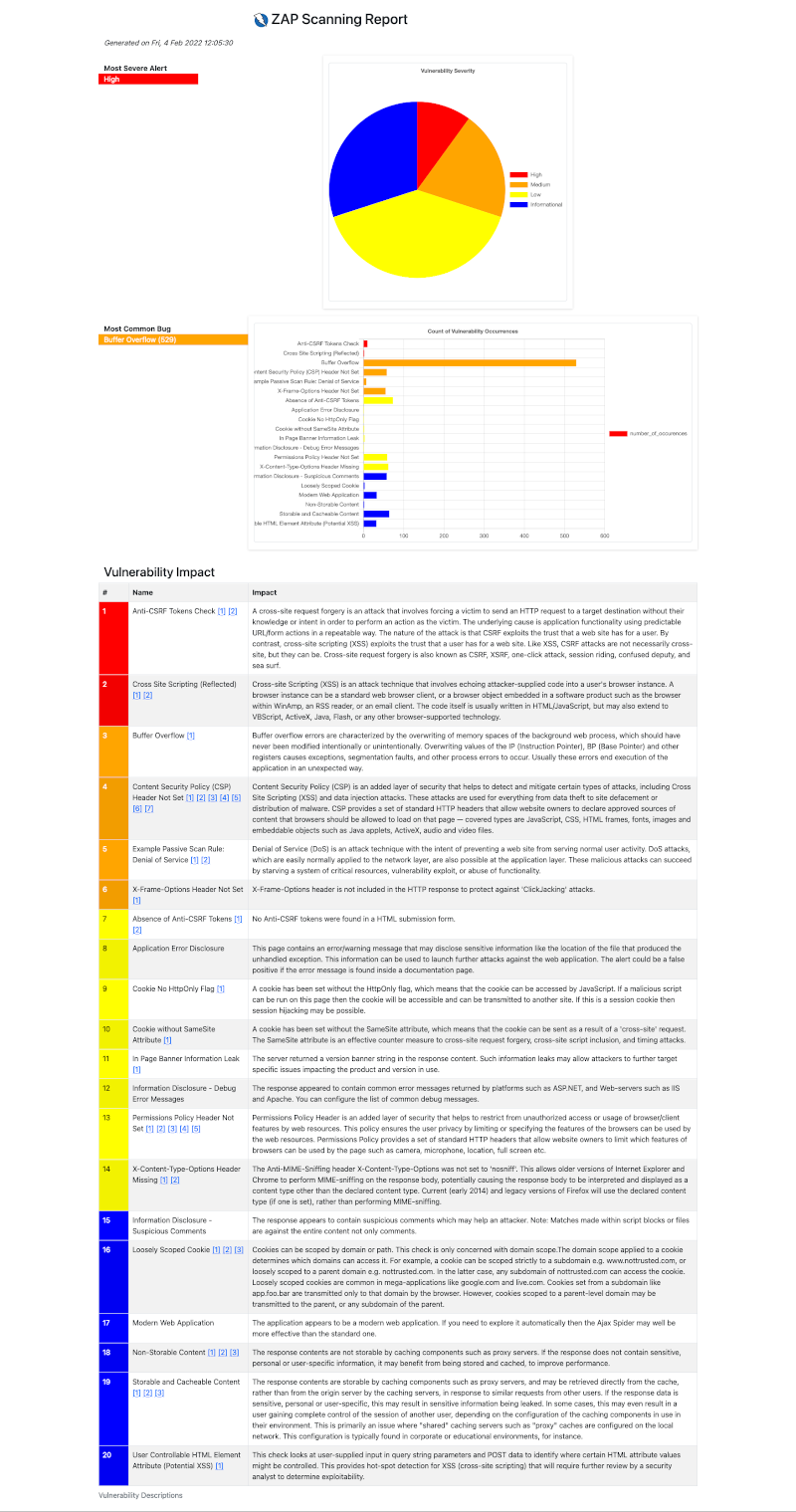
이 코드를 사용하여 ZAP를 자동화하고 주기적으로 웹사이트 취약점을 점검하고 결과를 수집할 수 있습니다. 필요에 따라 스캔을 실행하는 주기를 조절할 수 있습니다.
JSON 결과를 Elasticsearch에 저장하려면 Elasticsearch 서버와 연동하여 데이터를 색인해야 합니다. Elasticsearch는 REST API를 통해 데이터를 색인하고 검색할 수 있습니다. 먼저 Elasticsearch 서버를 설정하고, Python에서 Elasticsearch 라이브러리를 사용하여 데이터를 색인하는 코드를 작성해야 합니다.
아래는 Elasticsearch에 JSON 데이터를 저장하는 예제 코드입니다. 코드를 실행하기 전에 Elasticsearch 서버를 설정하고 Elasticsearch Python 클라이언트를 설치해야 합니다.
import time
import json
from datetime import datetime
from zapv2 import ZAPv2
from elasticsearch import Elasticsearch
# Elasticsearch 서버 설정 (Elasticsearch 호스트 및 포트에 맞게 설정하세요)
elasticsearch_host = "localhost"
elasticsearch_port = 9200
# 대상 웹사이트 설정
target_sites = [
"https://example.com", # 추가 대상 사이트
"https://example2.com",
]
# ZAP Docker 서비스 URL 설정
zap_url = "http://your-docker-host-ip:8080" # ZAP Docker 서비스 URL
# ZAP 프록시 시작
zap = ZAPv2(proxies={'http': zap_url, 'https': zap_url})
# 현재 날짜 가져오기 (년월일 시분초 형식)
current_date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Elasticsearch 클라이언트 연결
es = Elasticsearch([{'host': elasticsearch_host, 'port': elasticsearch_port}])
# 대상 사이트 목록을 반복해서 점검
for site in target_sites:
print(f"Scanning {site}...")
try:
# ZAP에서 사이트 추가
zap.urlopen(site)
# Active 스캔 시작
scan_id = zap.ascan.scan(site)
# 스캔이 완료될 때까지 대기
while int(zap.ascan.status(scan_id)) < 100:
print(f"Scan progress: {zap.ascan.status(scan_id)}%")
time.sleep(5) # 5초 대기
print(f"Scan for {site} complete.")
# JSON 리포트 생성
json_report = json.loads(zap.core.jsonreport())
# Elasticsearch에 JSON 데이터 색인
es.index(index='zap_reports', doc_type='_doc', body={
'site': site,
'report': json_report,
'scan_date': current_date
})
except Exception as e:
print(f"Error scanning {site}: {str(e)}")
finally:
# 현재 사이트의 진단이 완료되었으므로 ZAP 세션을 종료
zap.core.new_session()
# ZAP 종료
zap.core.shutdown()위 코드는 Elasticsearch Python 클라이언트를 사용하여 JSON 데이터를 Elasticsearch에 색인합니다. Elasticsearch 호스트와 포트를 적절하게 설정하고, 데이터를 어떤 인덱스에 저장할지를 설정하여 사용하세요.
Elasticsearch에 JSON 데이터를 색인하면 JSON 데이터의 하위 객체 값도 검색 가능하게 됩니다. Elasticsearch는 JSON 데이터를 저장할 때, 각 필드와 하위 객체를 색인하므로, 필드와 하위 객체의 내용을 검색할 수 있습니다.
예를 들어, 다음과 같은 JSON 데이터를 Elasticsearch에 색인한다고 가정해 봅시다.
{
"site": "https://example.com",
"report": {
"summary": "This is a summary",
"details": {
"vulnerabilities": [
{
"name": "Vuln1",
"severity": "High"
},
{
"name": "Vuln2",
"severity": "Medium"
}
]
}
},
"scan_date": "2023-09-19 14:30:00"
}이 데이터를 Elasticsearch에 색인하면, "site", "report", "summary", "details", "vulnerabilities", "name", "severity", "scan_date" 등의 필드와 하위 객체가 모두 색인됩니다.
그런 다음 Elasticsearch에서 검색할 때 JSON 데이터의 하위 객체 값을 검색할 수 있습니다. 예를 들어, "severity" 필드 값이 "High"인 보안 취약점을 찾고자 한다면 Elasticsearch 쿼리를 사용하여 검색할 수 있습니다.
from elasticsearch import Elasticsearch
# Elasticsearch 호스트 및 포트 설정
elasticsearch_host = "localhost"
elasticsearch_port = 9200
# Elasticsearch 클라이언트 연결
es = Elasticsearch([f"{elasticsearch_host}:{elasticsearch_port}"])
# Elasticsearch에서 "severity" 필드가 "High"인 문서 검색
query = {
"query": {
"match": {
"report.details.vulnerabilities.severity": "High"
}
}
}
# 검색 실행
results = es.search(index="zap_reports", body=query)
# 검색 결과 출력
for hit in results["hits"]["hits"]:
print(hit["_source"])위 코드에서는 Elasticsearch 쿼리를 사용하여 "severity" 필드가 "High"인 문서를 검색하고 검색 결과를 출력합니다. 이렇게 하면 JSON 데이터의 하위 객체 값을 검색할 수 있습니다.
Elasticsearch에 저장된 데이터를 Grafana를 통해 도식화하려면 다음 단계를 따라야 합니다.
Grafana는 Elasticsearch 데이터를 시각화하기 위한 강력한 도구 중 하나입니다.
- Grafana 설치 및 설정:
- Grafana를 설치하고 실행합니다.
- 웹 브라우저에서 Grafana 대시보드에 액세스하고 초기 설정을 수행합니다.
- Elasticsearch 데이터 원본 설정:
- Grafana 대시보드에서 "Configuration" 메뉴로 이동하고 "Data Sources"를 선택합니다.
- "Add data source"를 클릭하여 Elasticsearch 데이터 원본을 추가합니다.
- Elasticsearch 호스트 및 포트를 지정하고 인증 정보 (사용자 이름 및 비밀번호)를 입력합니다. 필요에 따라 SSL 설정을 구성합니다.
- 대시보드 및 패널 생성:
- "Create" 메뉴로 이동하고 "Dashboard"를 선택하여 새로운 대시보드를 만듭니다.
- 대시보드에 패널을 추가하려면 "Add new panel"을 선택합니다.
- "Query" 섹션에서 Elasticsearch 데이터 원본을 선택하고 쿼리를 작성합니다. 예를 들어, 필드 이름 및 필터를 지정하여 데이터를 가져올 수 있습니다.
- 시각화 타입 선택:
- 패널에서 "Visualization" 탭을 선택하고 원하는 시각화 타입 (예: 선 그래프, 막대 그래프, 표 등)을 선택합니다.
- 필요한 설정 (축, 레전드, 색상 등)을 구성합니다.
- 대시보드 저장:
- 대시보드를 저장하고 이름을 지정합니다.
- 대시보드 공유 및 배포:
- 필요에 따라 대시보드를 다른 사용자와 공유하거나 Grafana 대시보드를 웹 페이지에 내장하여 배포합니다.
여기서는 예제 코드를 통해 Elasticsearch 데이터를 Grafana로 시각화하는 간단한 예를 제시합니다. 이 코드를 사용하려면 Grafana와 Elasticsearch가 이미 설치되어 있어야 합니다. Elasticsearch 데이터를 조회하고 Grafana 대시보드에서 사용할 수 있는 Prometheus 형식의 지표로 변환하는 중간 프로세스가 필요합니다. 이를 위해 Metricbeat 또는 Logstash와 같은 도구를 사용할 수 있습니다.
예제 코드:
# Metricbeat 설정 예시 (metricbeat.yml)
metricbeat.modules:
- module: elasticsearch
metricsets:
- node
- index
- cluster
hosts: ["http://your-elasticsearch-host:9200"]
username: your-username
password: your-passwordMetricbeat는 Elasticsearch 데이터를 수집하여 Prometheus 형식으로 내보낼 수 있습니다. 그런 다음 Grafana에서 이러한 지표를 사용하여 대시보드를 만들 수 있습니다.
위에서 제시한 단계를 따라 Elasticsearch 데이터를 Grafana로 시각화하는 데 필요한 작업을 수행할 수 있을 것입니다. 그러나 Grafana 및 Elasticsearch의 구체적인 설정 및 사용 사례에 따라 추가적인 설정이 필요할 수 있습니다.
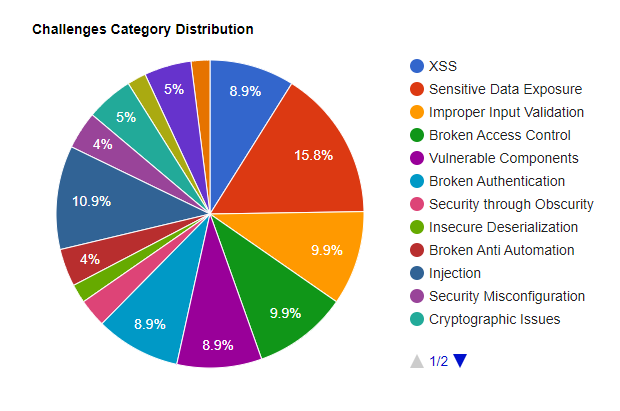
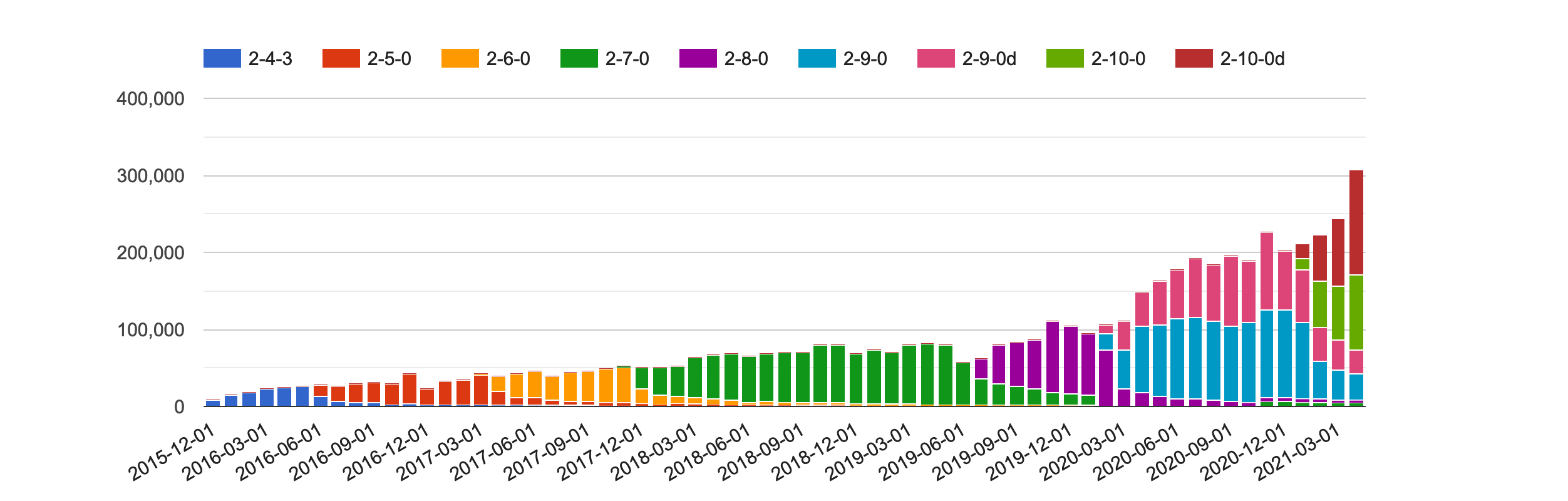




댓글