
OpenSearch 3.0은 AI 시대의 요구에 부응하여 벡터 검색 성능과 검색 인프라를 대폭 강화한 메이저 릴리즈입니다.
🚀 성능 및 구조 개선
- 성능 향상: OpenSearch 1.3 대비 최대 9.5배의 성능 향상을 달성했습니다.
- GPU 가속 지원: NVIDIA cuVS 엔진 기반의 GPU 가속을 통해 벡터 인덱싱 속도를 최대 9.3배 향상시키고, 운영 비용을 최대 3.75배 절감할 수 있습니다.
- Derived Source 기능: 벡터 데이터를 JSON 소스에서 분리하여 저장소 사용량을 최대 3배 절감하고, 쿼리 성능을 최대 30배 향상시킵니다.
- Lucene 10 기반: 최신 검색 라이브러리 도입이 되었습니다.
- Java 21, 모듈 아키텍처 도입: 유지보수성과 확장성을 확보합니다.
🤖 AI 및 벡터 검색 기능 강화
- Model Context Protocol (MCP) 지원: AI 에이전트(Agent)와의 연동을 위한 MCP를 지원하여, AI 기반 검색 및 추천 시스템의 유연성을 높였습니다.
- 벡터 엔진 개선: GPU 가속과 함께 벡터 엔진의 처리 속도와 효율성을 대폭 향상시켜, 대규모 벡터 데이터 처리에 최적화되었습니다.
- Hybrid Search 기반 설계: RAG 구조 적용이 가능합니다.
🔄 데이터 처리 및 전송 효율성 강화
- gRPC 지원: 클라이언트-서버 및 노드 간 통신에 gRPC를 도입하여 데이터 전송 속도와 효율성을 향상시켰습니다.
- Pull 기반 데이터 수집: Kafka, Kinesis 등 외부 스트리밍 시스템에서 데이터를 직접 가져오는 구조를 지원하여, 데이터 수집의 유연성과 제어력을 강화했습니다.
- Reader-Writer 분리: 검색과 인덱싱 작업을 분리하여 각 작업의 안정성과 성능을 확보하였습니다.
🏗️ 검색 인프라 및 플랫폼 개선
- Lucene 10 업그레이드: 검색 인프라를 현대화하여 병렬 작업 성능을 향상시키고, 검색 기능을 고도화하였습니다.
- Java 21 최소 지원 런타임: 최신 언어 기능과 성능을 활용할 수 있도록 Java 21을 최소 지원 런타임으로 설정하였습니다.
- Java 모듈 시스템 도입: 모놀리식 구조를 라이브러리 기반으로 전환하여 유지보수성과 확장성을 향상시켰습니다.
OpenSearch 3.0은 AI 및 RAG 기반 검색 수요 증가에 대응하여 벡터 검색 성능, 데이터 처리 효율성, 검색 인프라의 현대화를 통해 차세대 검색 플랫폼으로 자리매김하였습니다. 특히 GPU 가속, MCP 지원, gRPC 도입 등은 AI 기반 검색 및 대규모 데이터 처리에 큰 도움이 될 것입니다.
Elasticsearch vs OpenSearch 비교
| 항목 | Elasticsearch | OpenSearch |
|---|---|---|
| 라이선스 | Elastic License 2.0 / AGPLv3 (2024년 9월부로 오픈소스 재전환) | Apache 2.0 완전 오픈소스 |
| 출시 배경 | Elastic 사에서 독자 개발 | Elasticsearch 7.10을 기반으로 AWS 주도로 포크 |
| Kibana | 매우 강력하고 다양한 시각화 제공 | OpenSearch Dashboards는 비교적 느리고 버그 존재 |
| SQL 쿼리 | 자체 DSL + SQL API, 변환 처리 우수 | SQL 지원은 있으나 구현 방식이 다름 |
| API 호환성 | Elastic 고유 기능 존재 (ex. enrich processor 등) | 대다수 7.10 기반 API 호환, 일부 예외 존재 (search_after 등) |
| 벡터 검색 | FAISS 기반, Elastic 전용 기능 | HNSW 기반 벡터 검색, GPU 가속 등 강화 |
| 클라우드 지원 | Elastic Cloud (AWS 내에서 동작) | AWS OpenSearch Service |
| 성능 튜닝 | Elastic이 소폭 우위 (Dynamic Mapping 최적화 등) | 직접 호스팅 시 거의 유사한 수준 도달 가능 |
실사용자 경험 및 커뮤니티 통찰
✅ 장점
kt-search와 같이 Elastic과 OpenSearch 모두 지원하는 커뮤니티 클라이언트 존재- 대부분의 표준 검색/로그 수집 기능은 여전히 유사
- GPU 벡터 검색, derived sources, gRPC 등으로 OpenSearch는 AI/벡터 검색에 집중
❗ 단점
- OpenSearch는 enrich processor 등 고급 기능 부재
- Dashboards UI 느리고 버그 많음 (Kibana 대비)
- OpenSearch 커뮤니티는 Elastic 대비 커뮤니티 활력과 검증 부족
- 대규모 마이그레이션 시 모든 데이터 재인덱싱 필요
🔍 경험 기반 사용 팁
- HNSW 구현 성능은 탁월하지만 RAM 자원 요구 큼
- KNN 벡터 검색은 "RAM 전체 그래프 로딩"이 병목 → 메모리 관리 중요
- 성능은 대부분 “임베딩 품질 + 인덱스 튜닝”에 의존
어떤 환경에서 무엇을 선택할 것인가?
| 사용 시나리오 | 추천 제품 | 비고 |
|---|---|---|
| 클라우드 중심, 안정성 중시 | Elastic Cloud | 성숙한 SaaS, 강력한 Kibana |
| 오픈소스 선호, 벡터 중심 AI 검색 | OpenSearch 3.0 | GPU 가속, 확장성 우수 |
| 기존 Elasticsearch 유저 | Elastic 유지 or 신중한 마이그레이션 | 마이그레이션 비용 큼 |
| 완전 오픈소스 기반 제품 지향 | OpenSearch | AGPL 걱정 없는 Apache 2.0 |
📎 참고 링크
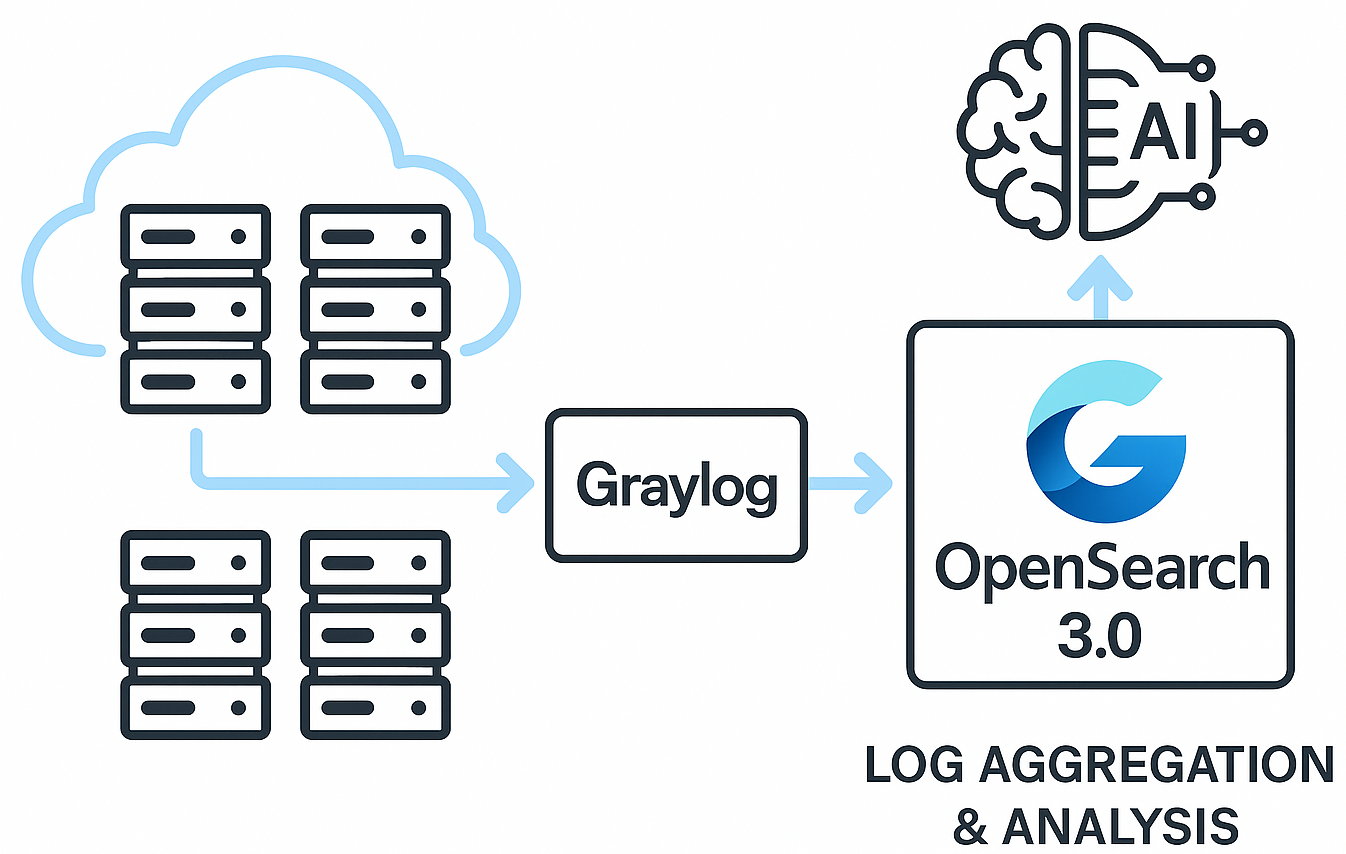

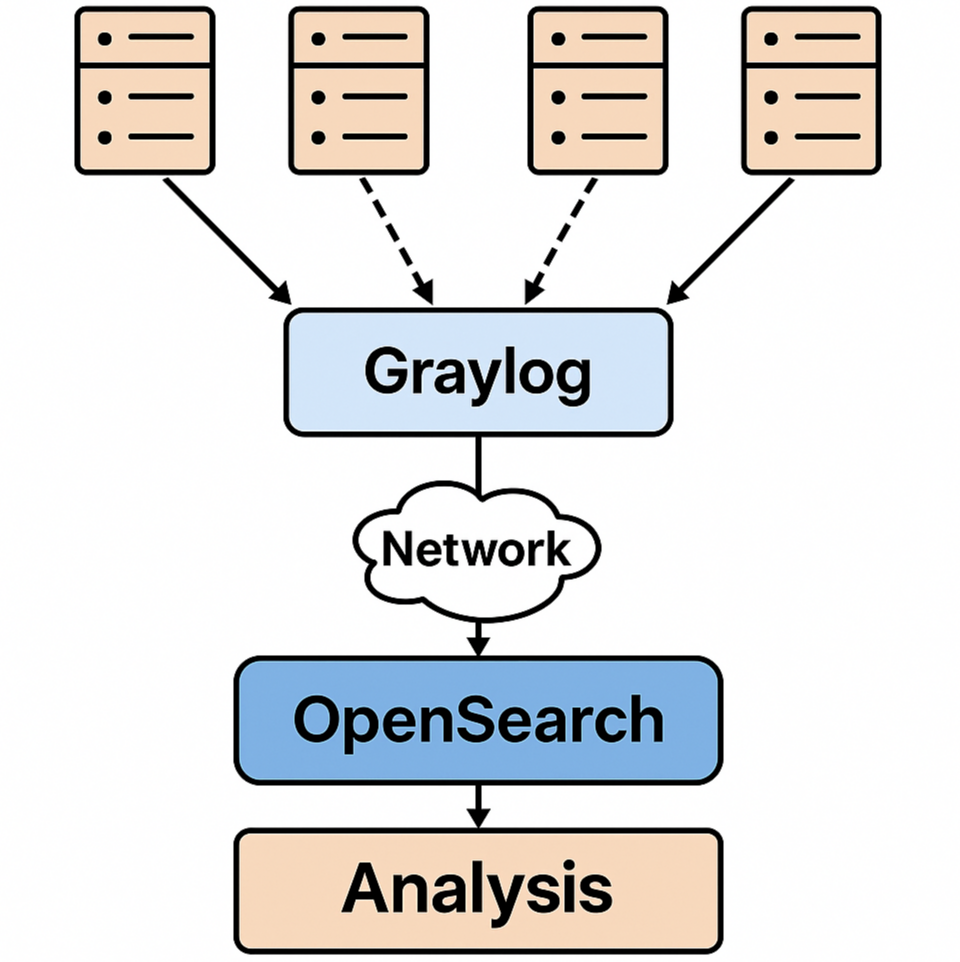
로그와 관련해서 대량 서버에서 순수하게 syslog 수집을 목적으로 한다면, Elastic Stack(ELK, OpenSearch 포함)과 함께 자주 비교되는 대안이 바로 Graylog입니다. 아래는 Graylog를 중심으로, syslog 수집에 필요한 주요 요소별로 Elastic Stack/OpenSearch 기반 시스템과 비교 분석한 결과입니다.
Graylog vs Elastic Stack (ELK/OpenSearch) – syslog 수집 목적 중심 비교
1. 아키텍처 구성 및 설치 용이성
| 항목 | Graylog | Elastic Stack (ELK/OpenSearch) |
|---|---|---|
| 구성 요소 | - Graylog 서버 (UI 및 파이프라인) - Elasticsearch or OpenSearch (저장소) - MongoDB (메타정보 저장) - 수집기: syslog, sidecar, beats |
- Elasticsearch / OpenSearch - Logstash (또는 Filebeat, rsyslog) - Kibana or OpenSearch Dashboards |
| 설치 복잡도 | 중간 수준: 공식 Docker Compose 제공, syslog 입력 포함되어 있음 | 복잡: Logstash 필터 구성, Kibana 설정, 다양한 인덱스 템플릿 설정 필요 |
| 기본 syslog 지원 | 내장된 Syslog 입력 포트 지원 (514/UDP) | Filebeat/rsyslog/Logstash를 통해 별도 구성 필요 |
결론: Graylog는 syslog 수집 전용으로는 보다 간단한 아키텍처를 제공함
2. syslog 수집 및 파싱 기능
| 항목 | Graylog | ELK / OpenSearch |
|---|---|---|
| 기본 syslog 파싱 | 기본적으로 RFC3164, RFC5424 파서 제공 | Logstash 혹은 rsyslog 설정 필요 (자체 grok 패턴 또는 dissect) |
| 파싱 방식 | UI 기반 파이프라인 정의, 정규표현식 처리 | Logstash config, grok 패턴 수작업 |
| 필드 추출 UI | 있음 (pipeline rules) | 없음, Kibana에선 수집 후 확인만 가능 |
| 상태 기반 파싱 | 가능 (메시지 기반 Rule 설정) | 복잡한 상황 처리 어려움 (Logstash 필터 구성 필요) |
결론: Graylog는 syslog 파싱이 시각적이고 직관적인 UI로 구성 가능, 운영 편의성 높음
3. 검색 및 시각화
| 항목 | Graylog | Kibana / OpenSearch Dashboards |
|---|---|---|
| 검색 UI | 실시간 검색에 특화, stream 필터 기반 | Discover 중심, dashboard 구성 후 분석 |
| 시각화 기능 | 제한적 (차트, 테이블 등) | Kibana는 매우 강력한 시각화 도구 보유 |
| 사용자 편의성 | Stream, Alert, Dashboard 등 명확한 용도 구분 | 매우 유연하나, 초기 설정 복잡 |
결론: 검색만 집중한다면 Graylog가 빠름, 시각화와 대시보드 활용은 Elastic이 우수
4. 확장성 및 대량 처리 성능
| 항목 | Graylog | ELK / OpenSearch |
|---|---|---|
| 수집 처리량 | 중간 이상 (수천 EPS 이상도 가능) | 대규모 (수만 EPS 이상 처리 가능) |
| 스케일 아웃 | 가능 (Graylog node clustering) | 매우 유연 (Beats, Logstash 수평 확장 가능) |
| 병목 요소 | MongoDB 및 stream filter 처리 시 부하 | Logstash 또는 Elasticsearch indexing bottleneck |
결론: 중소 규모까지는 Graylog로 충분하며, 대규모 분산 로그 처리는 ELK가 유리
5. 보안 및 역할 기반 접근 제어 (RBAC)
| 항목 | Graylog | Elastic / OpenSearch |
|---|---|---|
| 기본 RBAC | 있음 (role-based stream 접근 제어) | Elastic은 유료 X-Pack, OpenSearch는 Security Plugin으로 가능 |
| TLS 암호화 | 지원 | 지원 |
| 멀티 테넌시 | 지원 (stream 기반 분리) | 지원 (OpenSearch는 namespace/tenant 분리, Elastic은 유료 기능) |
결론: Graylog는 기본적으로도 보안 접근 제어가 잘 구성됨
6. 유지보수 및 운영 편의성
| 항목 | Graylog | Elastic Stack |
|---|---|---|
| 로그 수집 파이프라인 유지 | UI에서 파이프라인 관리 | Logstash grok 또는 ingest pipeline 직접 설정 |
| 운영 모니터링 | Web UI에서 시스템 상태, JVM 상태 모니터링 가능 | Stack Monitoring 별도 구성 필요 |
| 인덱스 롤오버 | GUI에서 자동 구성 가능 | ILM 또는 manual rollover 설정 필요 |
결론: Graylog는 단순 로그 수집 목적의 운영성이 뛰어남
7. 라이선스 및 오픈소스 정책
| 항목 | Graylog | Elastic | OpenSearch |
|---|---|---|---|
| 오픈소스 여부 | GPLv3 오픈소스 (Graylog Open) | 일부 기능 유료 (Elastic License) | Apache 2.0 완전 오픈소스 |
| 유료 기능 | SIEM, archive 등은 Graylog Enterprise | 보안, 머신러닝 등 유료 | 대부분 무료, Amazon이 후원 |
결론: syslog 수집만 고려한다면 Graylog Open 또는 OpenSearch 모두 적합
종합 결론
| 조건 | 추천 솔루션 |
|---|---|
| syslog 수집 전용, 설치 간단, UI 기반 관리 원함 | Graylog |
| 대규모 로그 처리, 복합 이벤트 처리, 커스텀 대시보드 필수 | ELK / OpenSearch |
| 보안 접근 제어 + 멀티 유저 환경 | Graylog 또는 OpenSearch Security Plugin |
| AI 기반 로그 분석, SIEM 구축 고려 중 | Elastic Stack (유료 포함) 또는 Wazuh 등 |
운영 시 체크포인트
- 수집 성능(EPS) 요구량 계산 후 적절한 아키텍처 선정
- TLS / RBAC 적용 여부 판단 (Graylog는 기본 제공, OpenSearch도 가능)
- 파싱 규칙 유지 가능성: 운영자가 직접 관리할 수 있는 UI 여부 중요
- 백업/보관/보존 정책 적용 필요 시 Elasticsearch 기반 솔루션 유리
아래는 Graylog를 Docker Compose로 구성하고, syslog 수집 및 파싱까지 설정하는 예시입니다.
1. Graylog Docker Compose 구성 예시
version: '3.8'
services:
mongo:
image: mongo:6
container_name: mongo
restart: always
opensearch:
image: opensearchproject/opensearch:2.11.1
container_name: opensearch
environment:
- discovery.type=single-node
- plugins.security.disabled=true
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- opensearch-data:/usr/share/opensearch/data
ports:
- "9200:9200"
graylog:
image: graylog/graylog:5.1
container_name: graylog
depends_on:
- mongo
- opensearch
environment:
- GRAYLOG_PASSWORD_SECRET=somepasswordpepper
- GRAYLOG_ROOT_PASSWORD_SHA2=<SHA2_HASHED_PASSWORD>
- GRAYLOG_HTTP_EXTERNAL_URI=http://localhost:9000/
entrypoint: /usr/bin/tini -- wait-for-it opensearch:9200 -- /docker-entrypoint.sh
ports:
- "9000:9000" # Graylog 웹 인터페이스
- "1514:1514/udp" # Syslog 수신 (UDP)
- "12201:12201/udp" # GELF 수신
volumes:
- graylog-journal:/usr/share/graylog/data/journal
volumes:
opensearch-data:
graylog-journal:비밀번호 해시 생성 방법
echo -n 'admin1234' | sha256sum결과의 첫 번째 필드를 GRAYLOG_ROOT_PASSWORD_SHA2에 입력하세요.
2. Syslog Input 구성
Graylog 웹 UI → System → Inputs → Launch new input
설정 예시
- Input Type:
Syslog UDP - Bind address:
0.0.0.0 - Port:
1514 - Override source: 빈칸
- Store full message: 체크
- Allow overriding date: 체크
3. Pipeline Rule 구성 (RFC3164 파서 예시)
Graylog는 수집한 메시지에 대해 Pipeline Rules를 이용해 필드를 추출하거나 변경할 수 있습니다.
예제: Jun 11 08:12:34 hostname appname[pid]: message 형태 파싱
1단계: Pipeline Rule 생성
rule "parse rfc3164 syslog"
when
has_field("message") &&
contains(to_string($message.message), ":")
then
let syslog_msg = regex("^(\\w{3}\\s+\\d+\\s+\\d+:\\d+:\\d+)\\s+(\\S+)\\s+(\\S+?)(?:\\[(\\d+)\\])?:\\s*(.*)$", to_string($message.message));
set_field("timestamp_string", syslog_msg["0"]);
set_field("syslog_hostname", syslog_msg["1"]);
set_field("syslog_program", syslog_msg["2"]);
set_field("syslog_pid", syslog_msg["3"]);
set_field("syslog_message", syslog_msg["4"]);
end2단계: Pipeline 생성 및 연결
- System → Pipelines → Create pipeline
- 이름:
syslog_parser - Description:
Parses basic RFC3164 messages
- 이름:
- Stage 0에 위 rule 추가
- System → Connectors → Stream에서 해당 파이프라인을
Syslog UDPInput에 연결
4. 결과 예시
입력 메시지
Jun 11 08:12:34 web01 nginx[1234]: access log line추출된 필드
| 필드명 | 값 |
|---|---|
| timestamp_string | Jun 11 08:12:34 |
| syslog_hostname | web01 |
| syslog_program | nginx |
| syslog_pid | 1234 |
| syslog_message | access log line |
운영 팁
- 운영 환경에서는 syslog 포트(514/UDP)는 루트 권한 필요 →
iptables또는setcap활용하거나 포트 포워딩 필요 - Graylog에 TLS 적용 시 reverse proxy(NGINX 등)를 사용하는 것이 일반적
- 수집량이 많은 경우,
journal디스크 경로 용량 주의 필요 - OpenSearch 대신 Elasticsearch도 사용 가능하나, 버전 호환성 주의
Graylog로 로그를 전송하기 위한 rsyslog 및 syslog-ng 설정 예제입니다. 이 구성은 특히 서버가 많고 syslog만 수집하려는 환경에서 매우 효율적으로 사용됩니다.
1. rsyslog 설정 예제 (UDP/TCP 전송)
A. 기본 UDP 전송 설정
📍 설정 파일: /etc/rsyslog.d/90-graylog.conf
*.* @graylog.example.com:1514@→ UDP 전송graylog.example.com→ Graylog 서버 IP 또는 호스트명1514→ Graylog Syslog UDP Input 포트
B. TCP 전송 (보다 신뢰성 있는 전송)
*.* @@graylog.example.com:1514@@→ TCP 전송
C. 포맷 지정 (RFC5424 등)
module(load="imuxsock") # local syslog
module(load="imklog") # kernel log
$template GRAYLOG,"<%pri%>%protocol-version% %timestamp:::date-rfc3339% %hostname% %app-name% %procid% %msgid% %msg%\n"
*.* @@graylog.example.com:1514;GRAYLOG🚀 재시작
sudo systemctl restart rsyslog2. syslog-ng 설정 예제
A. Graylog 전송을 위한 구성
📍 설정 파일: /etc/syslog-ng/conf.d/graylog.conf
destination d_graylog {
udp("graylog.example.com" port(1514));
};
log {
source(s_src); # 기본 source 정의 확인
destination(d_graylog);
};graylog.example.com: Graylog 서버 IP 또는 호스트명port(1514): Graylog에서 열린 Syslog Input 포트
B. TCP 또는 TLS 전송
destination d_graylog_tcp {
tcp("graylog.example.com" port(1514));
};
# 또는 TLS
destination d_graylog_tls {
tcp("graylog.example.com" port(1514)
tls(
ca-dir("/etc/syslog-ng/ca.d")
peer-verify(optional-untrusted)
)
);
};🚀 재시작
sudo systemctl restart syslog-ngGraylog Input 설정 요약
Graylog 웹 UI → System → Inputs → Syslog UDP or TCP 생성 시 다음 정보를 참고하세요.
| 설정 항목 | 값 |
|---|---|
| Port | 1514 (또는 원하는 포트) |
| Bind address | 0.0.0.0 |
| Store full message | 체크 |
| Allow override date | 체크 |
추천 사항
- 서버 수가 많다면 TLS 적용 권장 (
imtcportls설정) - 포맷 표준화 필요 시 rsyslog의
template또는 syslog-ng의rewrite기능 사용 - 모든 로그 전송을 중앙에서 모니터링하려면,
programname,hostname,severity별 필터링 및 stream 설정 필수
Graylog에서 다양한 로그 포맷을 처리하기 위해선 Pipeline Rule을 활용하는 것이 매우 유용합니다. 특히 JSON, CSV, Syslog, Apache/Nginx, 애플리케이션 로그 등 포맷별로 필드를 추출하고 정제하는 데 효과적입니다. 아래는 실제 운영 환경에서 자주 사용하는 로그 포맷별 Pipeline Rule 예시입니다.
1. JSON 로그 메시지 처리
rule "parse_json_log"
when
has_field("message") &&
regex("^\\{.*\\}$", to_string($message.message))
then
let parsed = parse_json(to_string($message.message));
set_fields(parsed);
end✅ 설명
message필드가{}형식의 JSON이면 파싱하여 key/value 필드로 자동 분리
2. CSV 형식 로그 처리
rule "parse_csv_log"
when
has_field("message") &&
contains(to_string($message.message), ",")
then
let parts = split(to_string($message.message), ",");
set_field("src_ip", parts[0]);
set_field("dest_ip", parts[1]);
set_field("action", parts[2]);
end✅ 예시 로그
192.168.0.10,10.0.0.2,ALLOW3. Apache/Nginx Access Log 파싱
rule "parse_apache_access_log"
when
has_field("message") &&
contains(to_string($message.message), "HTTP")
then
let m = regex("^(\\S+) (\\S+) (\\S+) \\[(.*?)\\] \"(.*?)\" (\\d{3}) (\\d+)", to_string($message.message));
set_field("client_ip", m["0"]);
set_field("user_ident", m["1"]);
set_field("user_auth", m["2"]);
set_field("timestamp", m["3"]);
set_field("request", m["4"]);
set_field("http_status", m["5"]);
set_field("size", m["6"]);
end✅ 예시 로그
127.0.0.1 - frank [10/Oct/2024:13:55:36 +0000] "GET /apache_pb.gif HTTP/1.0" 200 23264. 방화벽 로그 (정규표현식 기반)
rule "parse_fw_log"
when
has_field("message") &&
contains(to_string($message.message), "SRC=")
then
let m = regex("SRC=(\\S+) DST=(\\S+) PROTO=(\\S+)", to_string($message.message));
set_field("src_ip", m["0"]);
set_field("dst_ip", m["1"]);
set_field("protocol", m["2"]);
end✅ 예시 로그
SRC=10.0.0.1 DST=192.168.1.5 PROTO=TCP SPT=443 DPT=546325. Docker 로그 (logspout 형태)
rule "parse_docker_log"
when
has_field("message") &&
contains(to_string($message.message), "container_name=")
then
let m = regex("container_name=(\\S+) log=(.*)", to_string($message.message));
set_field("docker_container", m["0"]);
set_field("docker_log", m["1"]);
end6. 커스텀 애플리케이션 로그 예시
rule "parse_app_log"
when
has_field("message") &&
contains(to_string($message.message), "event_id=")
then
let m = regex("event_id=(\\d+) user=(\\S+) status=(\\S+)", to_string($message.message));
set_field("event_id", m["0"]);
set_field("user", m["1"]);
set_field("status", m["2"]);
end✅ 예시 로그
event_id=1004 user=jsmith status=FAILED공통 필드 정규화
rule "normalize_common_fields"
when
has_field("src_ip") && has_field("dst_ip")
then
rename_field("src_ip", "source_ip");
rename_field("dst_ip", "destination_ip");
end파이프라인 적용 순서
- System → Pipelines → Create pipeline
- Stage 0에 Rule 연결
- 해당 Input 또는 Stream에 Pipeline 연결
운영 시 주의사항
- 정규표현식은 최대한 구체적이고 빠르게 처리되도록 설계
- 메시지 구조가 자주 바뀌는 경우
try-catch형태 조건부 파싱 사용 - 수백 개 서버에서 전송되는 경우
pipeline processor부하 고려
Graylog에서는 로그 필터링과 알림 기능을 Stream과 Alert (Event & Notification) 시스템으로 설정합니다. 이 구조는 실시간 보안 분석 및 운영 알림 체계를 구축하는 데 핵심적인 요소입니다. 다음은 Stream 기반 필터링과 Event 알림 설정 예제입니다.
1. Stream 기반 로그 필터링 설정
Stream이란?
특정 조건에 맞는 로그만 필터링해서 분리 처리할 수 있는 실시간 필터링 채널
📍 예제: firewall 로그만 분리
① Stream 생성
- System → Streams → Create stream
- Title:
Firewall Logs - Index Set: default
- Description: "Firewall에서 발생한 로그만 필터링"
- Title:
② Rule 추가
- Add Stream Rule
- Field:
sourceorprogramname - Condition: match exact
- Value:
firewalld또는iptables
- Field:
③ Input 연결
Syslog UDP입력 설정 시, Stream을 연결하면 해당 조건을 만족하는 메시지만 해당 Stream으로 라우팅됨
2. Event 정의 + Alert Notification 설정
Event란?
일정 조건을 만족하는 로그가 감지되었을 때 하나의 사건(Event) 으로 감지하여 알림 트리거를 수행
📍 예제: 로그인 실패 감지 후 이메일 알림
① Event Definition 생성
- Alerts → Event Definitions → Create
- Title:
Login Failure Alert - Filter & Aggregation
- Type: Filter-based event
- Query:
message:"authentication failure" - Streams: (앞서 만든 특정 Stream 선택 가능)
- Condition
- Add: Trigger when count > 3 in 1 minute (ex: brute force)
② Custom Fields
- Extract
username,src_ip필드 설정 가능
③ Notification 정의
- Alerts → Notifications → Create
- Type: Email, Slack, HTTP, etc.
- Title:
Email to Security - Recipients:
security@company.com - Subject:
[Graylog Alert] Login Failures - Body Template 예
Alert: ${event_definition_title} Message: ${event.message} Source: ${event.source} Timestamp: ${event.timestamp}
④ Event → Notification 연결
- 생성한 Notification을 해당 Event Definition에 연결
예시 Query
SSH 로그인 실패 패턴 (pam)
message:"authentication failure" OR message:"Failed password for"웹 공격 감지 (WAF / Apache)
message:"SQL injection" OR message:"/etc/passwd"포트 스캔 감지 (fw log)
message:"port scan detected"운영 팁
| 목적 | 방법 |
|---|---|
| 특정 서비스 로그 필터링 | Stream + Field match |
| 이벤트 수 발생 시 알림 | Event Definition + Count 조건 |
| Slack 연동 | HTTP Notification + Slack Webhook URL |
| 대량 발생 방지 | Event → Alert → Notification에 throttling 설정 |
| 위험 레벨 구분 | Event field에 severity 설정 (ex: high, medium, low) |
실전 시나리오 예시
✔️ Stream: WAF Logs
- Field:
source == waf01.local - Field:
message contains attack
✔️ Event Definition
- Query:
message:SQLi OR message:XSS - Condition: count > 5 in 30 seconds
✔️ Notification
- Slack →
#sec-alerts - Subject:
"🚨 Web 공격 감지"




댓글