Elasticsearch 방대한 양의 데이터를 효과적으로 운영하기 위한 핫 데이터와 콜드 데이터 관리 방식
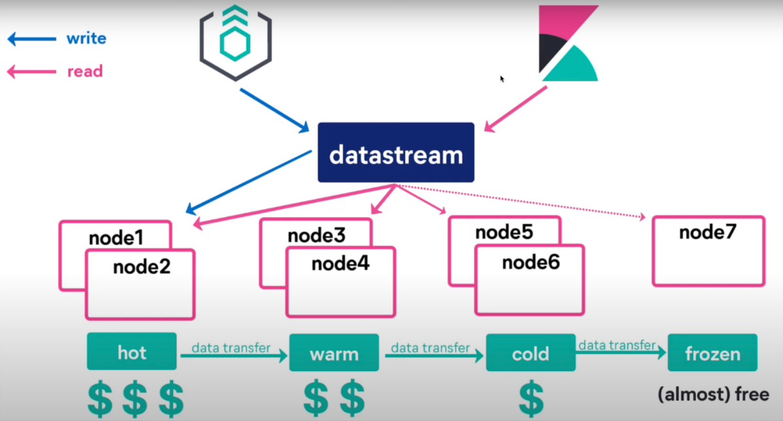
운영 환경에서 대량의 로그 데이터를 수집하고 관리할 때, 성능 최적화와 비용 효율성을 위해 데이터를 핫 데이터(자주 조회되는 최신 데이터)와 콜드 데이터(빈도 낮은 오래된 데이터)로 분류하여 관리하는 전략을 사용할 수 있습니다.
핫 데이터와 콜드 데이터 분류 전략
핫 데이터(Hot Data)
- 정의: 최근 수집된 데이터로, 조회 빈도가 높고 빠른 검색 성능이 필요한 데이터입니다.
- 저장 위치: Elasticsearch의 빠른 검색 인덱스에 저장합니다.
- 관리: 주로 Elasticsearch의 기본 노드에 저장되며, 고성능 디스크를 사용합니다.
콜드 데이터(Cold Data)
- 정의: 일정 기간이 지난 후 접근 빈도가 낮아진 데이터입니다.
- 저장 위치: 비용 효율적인 저장소(예: ClickHouse)로 이전하여 보관합니다.
- 관리: 주로 분석용으로 사용되며, 저장 비용이 저렴한 스토리지를 사용합니다.
Elasticsearch ILM (Index Lifecycle Management) 설정
Elasticsearch의 ILM 기능을 사용하여 데이터의 라이프사이클을 자동으로 관리할 수 있습니다.
ILM Policy 설정 예시
PUT _ilm/policy/my_ilm_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "7d"
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"allocate": {
"number_of_replicas": 1
},
"shrink": {
"number_of_shards": 1
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
}
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}- hot: 데이터를 7일간 저장하고, 인덱스를 롤오버합니다.
- warm: 7일 후 웜 페이즈로 이동하여 데이터 복제 및 샤드 수를 줄입니다.
- cold: 30일 후 콜드 페이즈로 이동하여 저비용 스토리지에 할당합니다.
- delete: 90일 후 데이터를 삭제합니다.
데이터 이전 자동화
Logstash를 사용하여 콜드 데이터를 ClickHouse로 이전하는 설정을 예시로 설명합니다.
Logstash Configuration Example (logstash.conf)
input {
elasticsearch {
hosts => ["localhost:9200"]
index => "your_index"
query => '{"query": {"range": {"@timestamp": {"lt": "now-30d"}}}}'
size => 500
scroll => "5m"
docinfo => true
}
}
filter {
# 필요한 필터 설정
}
output {
jdbc {
connection_string => 'jdbc:clickhouse://<ClickHouse-Host>:<Port>/<Database>'
driver_jar_path => '/path/to/clickhouse-jdbc-<version>.jar'
driver_class => 'ru.yandex.clickhouse.ClickHouseDriver'
statement => ['INSERT INTO table_name (field1, field2) VALUES(?, ?)', '[field1]', '[field2]']
}
}ClickHouse 설정 및 최적화
ClickHouse는 대량의 데이터를 빠르게 처리할 수 있도록 최적화된 데이터베이스입니다.
ClickHouse 테이블 생성 예시
CREATE TABLE logs (
date Date,
level String,
message String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(date)
ORDER BY (date, level);- PARTITION BY: 데이터 파티셔닝으로 쿼리 성능을 향상시킵니다.
- ORDER BY: 데이터 정렬을 통해 빠른 조회 성능을 보장합니다.
데이터 모니터링 및 유지관리
- Elasticsearch 모니터링: Kibana와 같은 도구를 사용하여 Elasticsearch 클러스터의 성능을 모니터링합니다.
- ClickHouse 모니터링: Grafana와 ClickHouse 플러그인을 사용하여 쿼리 성능 및 리소스 사용량을 모니터링합니다.
BI 도구 연동 및 데이터 활용
- Grafana 연동: ClickHouse 데이터를 Grafana와 연동하여 시각화 대시보드를 구성합니다.
- API 연동: ClickHouse의 HTTP 인터페이스를 사용하여 애플리케이션에서 데이터를 쿼리하고 분석합니다.
ClickHouse HTTP 쿼리 예시
curl -X POST 'http://<ClickHouse-Host>:<Port>/?query=SELECT+*+FROM+logs+WHERE+date+%3E%3D+%272022-01-01%27'위와 같은 방법으로 Elasticsearch에서 데이터를 효율적으로 관리하면서 성능 최적화를 도모할 수 있습니다. 핫 데이터와 콜드 데이터로 분류하여 저장하고, 필요에 따라 데이터를 이전하여 비용 효율적인 운영을 할 수 있습니다.
Elasticsearch (ES)에서 로그 데이터를 관리할 때 데이터가 방대해지고, 이로 인해 성능 문제가 발생하는 경우가 많습니다. 이를 해결하기 위해 핫 데이터는 Elasticsearch에서 계속 관리하고, 일정 시간이 지난 콜드 데이터는 ClickHouse 같은 분석 최적화 DB로 이전하는 전략이 효과적일 수 있습니다.
전반적으로 개념정리
1. 데이터 분류: 핫 데이터와 콜드 데이터
- 핫 데이터(Hot Data): 최근 데이터로, 빈번하게 접근하고 검색할 가능성이 높은 데이터입니다. Elasticsearch에서 계속 관리합니다.
- 콜드 데이터(Cold Data): 일정 시간이 지난 후 빈도가 낮은 접근을 받는 데이터로, 비용 효율적인 저장소인 ClickHouse로 이전합니다.
2. Elasticsearch의 ILM (Index Lifecycle Management) 설정
Elasticsearch의 ILM 기능을 사용하여 데이터의 라이프사이클을 자동으로 관리할 수 있습니다. ILM은 다음 단계로 구성됩니다.
- Roll over: 데이터 크기나 일정 기간이 되면 새 인덱스로 전환합니다.
- Warm Phase: 검색 빈도가 낮아지면 웜 페이즈로 이동합니다. 필요에 따라 데이터를 적절한 형식으로 변환할 수 있습니다.
- Cold Phase: 더 이상 활발히 사용되지 않는 데이터를 콜드 페이즈로 이동합니다. 이 단계에서 Elasticsearch의 저장 공간을 줄이기 위해 데이터를 압축하거나 삭제할 수 있습니다.
- Delete: 설정한 저장 기간이 지나면 데이터를 자동으로 삭제합니다.
3. 데이터 이전
- Logstash 또는 기타 ETL 도구 사용: 콜드 데이터를 Elasticsearch에서 ClickHouse로 이전하기 위해 Logstash, Apache NiFi, 또는 다른 ETL 도구를 사용할 수 있습니다. 이 도구들은 데이터 추출, 변환, 적재(ETL) 작업을 자동화하여 처리합니다.
- 데이터 포맷 및 스키마 정의: ClickHouse에 데이터를 저장하기 전에 적절한 데이터 포맷과 스키마를 정의해야 합니다. ClickHouse는 열 기반 스토리지이므로 분석 쿼리에 최적화된 스키마 설계가 중요합니다.
4. ClickHouse 설정 및 최적화
- 테이블 파티셔닝과 샤딩: 큰 데이터 세트를 효율적으로 관리하기 위해 ClickHouse에서는 테이블을 파티셔닝하고 샤딩할 수 있습니다. 이는 쿼리 성능을 향상시키고, 데이터 관리를 용이하게 합니다.
- 집계 및 머티리얼라이즈드 뷰: 자주 사용되는 쿼리 패턴에 대해 집계 테이블이나 머티리얼라이즈드 뷰를 설정하여 빠른 응답 시간을 보장할 수 있습니다.
5. 모니터링 및 유지관리
- 성능 모니터링: Elasticsearch와 ClickHouse 모두에서 성능 모니터링을 설정하여 시스템의 상태를 지속적으로 감시합니다.
- 정기적인 리뷰 및 최적화: 데이터 접근 패턴과 성능 데이터를 정기적으로 검토하고, 필요에 따라 인덱싱 전략이나 쿼리 최적화를 조정합니다.
6. 데이터 이전 자동화
데이터를 자동으로 Elasticsearch에서 ClickHouse로 이전하기 위한 자동화 프로세스를 설정합니다.
- 자동화 스크립트 작성: 콜드 데이터를 식별하고 이전하는 자동화된 스크립트를 개발합니다. 이 스크립트는 정기적으로 실행되며, 필요에 따라 Logstash 또는 Apache NiFi를 통해 데이터를 추출하고, ClickHouse로 전송합니다.
- API 활용: Elasticsearch 및 ClickHouse의 API를 활용하여 데이터 관리와 이전을 자동화합니다. Elasticsearch의 Scroll API나 Search After API를 사용하여 대량의 데이터를 효과적으로 추출할 수 있습니다.
7. 데이터 이전 시 고려사항
- 데이터 무결성 유지: 데이터를 이전할 때 원본 데이터의 무결성을 유지하는 것이 중요합니다. 이전 과정에서 데이터 손실이 발생하지 않도록 주의합니다.
- 보안 유지: 데이터 전송 과정에서 보안을 유지하기 위해 암호화 및 안전한 연결(예: SSL/TLS)을 사용합니다.
8. 데이터 접근 및 쿼리 성능 최적화
- 데이터 접근 전략 정의: 사용자가 콜드 데이터에 접근할 필요가 있을 때, ClickHouse에서 빠르게 접근할 수 있도록 적절한 인덱싱 및 쿼리 최적화 전략을 수립합니다.
- 성능 테스트: 실제 운영 환경에서 성능 테스트를 실시하여 데이터 이전 후의 쿼리 성능이 기대치를 만족하는지 확인합니다.
9. 운영 및 유지 보수
- 모니터링 도구 활용: Elasticsearch와 ClickHouse의 성능 모니터링을 위해 Kibana, Grafana 같은 도구를 활용하여 시스템의 상태를 지속적으로 모니터링합니다.
- 정기적인 백업 및 재해 복구 계획 수립: 데이터의 안정성을 보장하기 위해 정기적인 백업 및 재해 복구 계획을 수립하고 실행합니다.
10. 문서화 및 교육
- 문서화: 모든 데이터 이전 프로세스와 시스템 구성을 문서화하여 운영 팀과 개발 팀이 쉽게 참조할 수 있도록 합니다.
- 팀 교육: 데이터 이전 프로세스와 사용 도구에 대한 교육을 실시하여 팀원들이 시스템을 효과적으로 운영할 수 있도록 합니다.
데이터 라이프사이클 관리는 단순한 기술 실행을 넘어서 조직 전체의 데이터 전략과 밀접하게 연결되므로, 전체 비즈니스 목표와도 일치해야 합니다. 데이터를 Elasticsearch에서 ClickHouse로 이동하는 설정과 구현 과정과, 이전된 콜드 데이터를 활용하는 방법입니다.
Elasticsearch에서 ClickHouse로 데이터 이동 구성
1. 데이터 이전을 위한 환경 준비
- ClickHouse 설치 및 설정: ClickHouse 인스턴스를 설치하고, 필요한 데이터베이스와 테이블을 생성합니다. 테이블은 쿼리 패턴과 저장된 데이터 유형에 따라 설계합니다.
- Logstash 설치: Logstash를 사용하여 Elasticsearch에서 데이터를 추출하고 ClickHouse로 이전할 수 있습니다. Logstash 설치 후, 필요한 입력(input), 필터(filter), 출력(output) 플러그인을 설정합니다.
2. Logstash 설정
Logstash를 통해 Elasticsearch 데이터를 ClickHouse로 이동시키는 예제 설정은 다음과 같습니다.
input {
elasticsearch {
hosts => ["localhost:9200"]
index => "your_index"
query => '{"query": {"range": {"timestamp": {"lt": "now-1y"}}}}'
size => 500
scroll => "5m"
docinfo => true
}
}
filter {
# 필요한 필터 설정
}
output {
jdbc {
connection_string => 'jdbc:clickhouse://<ClickHouse-Host>:<Port>/<Database>'
driver_jar_path => '/path/to/clickhouse-jdbc-<version>.jar'
driver_class => 'ru.yandex.clickhouse.ClickHouseDriver'
statement => ['INSERT INTO table_name (field1, field2) VALUES(?, ?)', '[field1]', '[field2]']
}
}- 입력: Elasticsearch 인덱스에서 지정된 쿼리에 따라 데이터를 추출합니다.
- 출력: JDBC 출력 플러그인을 사용하여 ClickHouse로 데이터를 전송합니다. 적절한 JDBC 드라이버와 연결 문자열을 설정해야 합니다.
3. Logstash 실행
위의 설정 파일을 저장한 후, Logstash를 실행하여 데이터 이전을 시작합니다.
logstash -f logstash.conf콜드 데이터 활용 방법
1. ClickHouse에서 콜드 데이터 접근 및 분석
ClickHouse는 SQL 쿼리를 지원하므로, 콜드 데이터에 대한 질의 및 분석을 SQL 문을 통해 수행할 수 있습니다.
SELECT * FROM your_table
WHERE date BETWEEN '2022-01-01' AND '2022-12-31'
ORDER BY date DESC
LIMIT 100;2. BI 도구 연동
- Grafana, Tableau 등의 BI 도구와 ClickHouse를 연동하여 시각화할 수 있습니다. 각 도구에 따른 데이터 소스 연결 설정을 통해 인터랙티브한 대시보드를 구성할 수 있습니다.
3. API를 통한 데이터 접근
- REST API: ClickHouse는 HTTP 인터페이스를 통해 외부에서 SQL 쿼리를 실행할 수 있는 기능을 제공합니다. 이를 활용해 웹 서비스나 애플리케이션에서 콜드 데이터를 쿼리할 수 있습니다.
Kibana처럼 Elasticsearch(ES) 정보를 조회할 수 있는 도구 중 스마트폰에서 효과적으로 사용할 수 있는 몇 가지 앱과 오픈소스 솔루션을 소개합니다.
1. Elastic 공식 앱 (Elastic Stack Monitoring)
- Elastic에서 제공하는 공식 앱으로, Kibana를 포함한 Elasticsearch 클러스터의 모니터링 기능을 제공합니다.
- 기본적으로 모니터링 목적이 강하지만, 필요한 정보 조회도 가능하며, Elastic Cloud에 연결된 환경에서 주로 활용됩니다.
- 플랫폼: iOS, Android
- 장점: Elastic 공식 제공, 보안 연결이 용이
2. Search Guard Kibana Plugin (SG Plugin)
- Elasticsearch에 보안 기능을 추가해주는 Search Guard의 Kibana 플러그인입니다.
- Search Guard를 통해 모바일 브라우저에서도 Kibana 대시보드를 안전하게 조회할 수 있는 웹 접근을 제공합니다.
- 플랫폼: 모바일 브라우저에서 사용 가능
- 장점: 고급 보안 기능 제공
3. Kibana 모바일 브라우저 최적화
- Kibana 자체는 모바일 브라우저를 통해서도 사용이 가능하지만, UI가 데스크탑에 최적화되어 있어 약간 불편할 수 있습니다.
- 이를 해결하기 위해 사용자 정의 CSS를 적용하거나, 모바일 사용자를 위한 경량화된 대시보드를 만들어 사용하는 방법도 있습니다.
- 플랫폼: 모바일 브라우저
4. Kuzzle
- Kuzzle는 실시간 데이터 및 IoT 애플리케이션을 위한 오픈소스 백엔드입니다. Elasticsearch와 통합되어 다양한 기기에서 실시간 데이터를 조회하고 시각화하는 데 사용될 수 있습니다.
- 플랫폼: iOS, Android, 웹 브라우저
- 장점: 모바일 친화적인 UI, 실시간 데이터 처리에 강점
5. Grafana
- Grafana는 Elasticsearch와 통합하여 다양한 데이터 소스를 시각화하는데 사용될 수 있습니다.
- 모바일에서의 사용성이 우수하고, Elasticsearch뿐만 아니라 Prometheus 등 다양한 데이터 소스를 통합해서 볼 수 있어 유용합니다.
- 플랫폼: 모바일 브라우저, iOS, Android
- 장점: 다양한 데이터 소스 지원, 사용자 정의 대시보드
6. Termux + Kibana CLI
- Linux 환경에서 사용하는 Termux 앱을 통해 모바일에서 Kibana나 Elasticsearch에 CLI로 접근할 수 있습니다.
- 직접적인 UI는 없지만, CLI 명령어를 통해 간단한 조회나 설정을 할 수 있습니다.
- 플랫폼: Android (Termux)
7. Discover Mobile (iOS 전용)
- iOS 전용 앱으로 Elasticsearch 데이터를 조회할 수 있는 앱입니다.
- 검색, 필터링, 데이터를 조회할 수 있으며 Elasticsearch와 통합된 정보에 쉽게 접근할 수 있습니다.
- 플랫폼: iOS
- 장점: 사용자 친화적, 모바일 최적화
이 중에서 Elastic 공식 앱이나 Grafana가 가장 보편적이고, 사용자가 친숙하게 사용할 수 있는 도구들입니다.




댓글