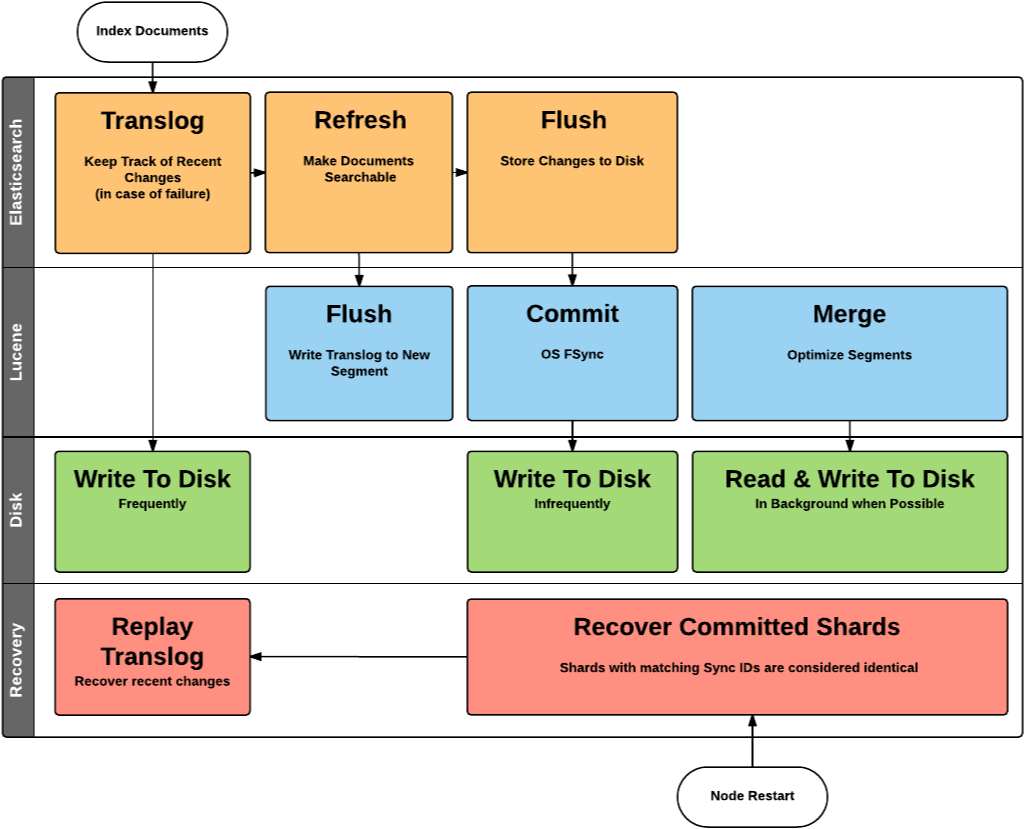
Elasticsearch에서 로그 데이터를 저장하고 일정 기간이 지나면 자동으로 삭제되는 방식과는 다르게, 영구적으로 데이터를 저장하고 RDBMS처럼 검색하고 활용하는 방법에 대해 설명드리겠습니다.
- 인덱스 설정 및 매핑 구성
영구적으로 데이터를 저장하려면 인덱스의 매핑과 설정을 적절히 구성해야 합니다. 특히, 로그 방식과는 다르게, 검색 및 분석에 최적화된 매핑을 설정하는 것이 중요합니다.PUT /my_persistent_index { "settings": { "number_of_shards": 1, "number_of_replicas": 1 }, "mappings": { "properties": { "timestamp": { "type": "date" }, "user_id": { "type": "keyword" }, "action": { "type": "text" }, "details": { "type": "text" } } } } - 데이터 인덱싱
데이터를 Elasticsearch에 인덱싱할 때, 위에서 정의한 매핑에 맞춰 데이터를 저장합니다.POST /my_persistent_index/_doc { "timestamp": "2024-07-08T10:00:00Z", "user_id": "user123", "action": "login", "details": "User logged in successfully" } - 검색 및 쿼리
데이터를 검색할 때, RDBMS에서 SQL 쿼리를 사용하는 것처럼 Elasticsearch DSL(Data Search Language)을 사용하여 쿼리를 작성할 수 있습니다.GET /my_persistent_index/_search { "query": { "match": { "user_id": "user123" } } } - 데이터 보존 정책 설정
데이터의 영구 보존을 위해서 인덱스의 보존 정책을 설정해야 합니다. 보존 정책을 설정하지 않으면, 데이터가 자동으로 삭제될 수 있습니다. 다음과 같이 ILM(Index Lifecycle Management)을 사용하여 데이터 보존 정책을 설정할 수 있습니다.PUT _ilm/policy/my_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "50GB", "max_age": "30d" } } }, "delete": { "min_age": "5y", "actions": { "delete": {} } } } } } PUT /my_persistent_index/_settings { "index.lifecycle.name": "my_policy", "index.lifecycle.rollover_alias": "my_persistent_index" } - 백업 및 스냅샷
데이터를 영구적으로 보존하기 위해서는 주기적으로 백업 및 스냅샷을 생성하는 것이 좋습니다. Elasticsearch는 스냅샷 기능을 제공하여 데이터를 백업할 수 있습니다.PUT /_snapshot/my_backup_repository { "type": "fs", "settings": { "location": "/mount/backups" } } PUT /_snapshot/my_backup_repository/snapshot_1 { "indices": "my_persistent_index", "ignore_unavailable": true, "include_global_state": false } - 모니터링 및 관리
Elasticsearch의 데이터 보존 정책이 잘 적용되고 있는지 모니터링하고, 필요시 설정을 조정하여 데이터 손실을 방지합니다.
이러한 단계를 통해 Elasticsearch에서 로그처럼 자동으로 삭제되지 않고, 영구적으로 데이터를 보존하고 RDBMS처럼 검색 및 활용할 수 있는 인덱스를 구성할 수 있습니다.
Elasticsearch 인덱스는 특정 기간 조건 없이 전체 데이터에서 검색하는 방법으로도 활용이 가능합니다. 이는 데이터의 구조와 매핑 설정에 따라 결정됩니다. 전체 데이터에서 검색하는 방식으로 인덱스를 구성하고 활용하는 방법을 설명드리겠습니다.
1. 인덱스 생성 및 매핑 설정
인덱스를 생성할 때 필요한 매핑을 설정합니다. 예를 들어, 사용자의 액션 로그를 저장하는 인덱스를 생성해보겠습니다.
PUT /user_actions
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"user_id": {
"type": "keyword"
},
"action": {
"type": "text"
},
"details": {
"type": "text"
}
}
}
}2. 데이터 인덱싱
데이터를 Elasticsearch에 인덱싱할 때, 설정된 매핑에 따라 데이터를 저장합니다.
POST /user_actions/_doc
{
"timestamp": "2024-07-08T10:00:00Z",
"user_id": "user123",
"action": "login",
"details": "User logged in successfully"
}3. 전체 데이터에서 검색
특정 기간 조건 없이 전체 데이터에서 검색하려면, 검색 쿼리에서 match_all 쿼리를 사용할 수 있습니다.
GET /user_actions/_search
{
"query": {
"match_all": {}
}
}또는 특정 필드에 대해 조건을 추가할 수도 있습니다.
GET /user_actions/_search
{
"query": {
"match": {
"user_id": "user123"
}
}
}4. 검색 최적화
데이터가 많아질수록 검색 성능이 중요해지므로, 검색 성능을 최적화하기 위해 다음과 같은 방법을 고려할 수 있습니다.
- 필드 데이터 유형 최적화: 자주 검색되는 필드의 데이터 유형을 적절히 설정하여 검색 성능을 향상시킵니다.
- 인덱스 최적화: 주기적으로 인덱스를 최적화하여 검색 속도를 개선합니다.
- 캐싱: 자주 검색되는 쿼리에 대해 Elasticsearch의 캐싱 기능을 활용합니다.
5. 예제 쿼리
다양한 예제 쿼리를 통해 데이터를 검색해보겠습니다.
- 특정 사용자 액션 검색
GET /user_actions/_search { "query": { "match": { "action": "login" } } } - 특정 사용자 ID로 검색
GET /user_actions/_search { "query": { "term": { "user_id": "user123" } } } - 복합 조건 검색
GET /user_actions/_search { "query": { "bool": { "must": [ { "match": { "user_id": "user123" }}, { "match": { "action": "login" }} ] } } }
이와 같이 설정하면 Elasticsearch 인덱스에서 특정 기간 조건 없이 전체 데이터에서 검색할 수 있으며, RDBMS와 유사한 방식으로 데이터를 활용할 수 있습니다. 필요한 경우 검색 쿼리에 조건을 추가하여 원하는 데이터를 더욱 정밀하게 검색할 수도 있습니다.
Elasticsearch는 본래 검색 및 분석을 위한 문서 지향 데이터 저장소로 설계되었으며, RDBMS처럼 전통적인 CRUD(생성, 읽기, 갱신, 삭제) 작업을 수행할 수 있지만 그 방식은 조금 다릅니다. Elasticsearch에서 데이터를 업데이트하고 삭제하는 방법을 설명드리겠습니다.
1. 데이터 업데이트
Elasticsearch에서는 문서를 업데이트할 때 전체 문서를 다시 인덱싱합니다. 부분 업데이트도 가능하지만, 실제로는 내부적으로 전체 문서를 다시 작성하게 됩니다.
기존 문서를 업데이트하려면 update API를 사용합니다.
POST /user_actions/_update/<document_id>
{
"doc": {
"action": "logout"
}
}스크립트를 사용한 부분 업데이트
특정 필드를 기준으로 부분 업데이트를 할 수 있습니다. 예를 들어, details 필드에 문자열을 추가하려면 다음과 같이 합니다.
POST /user_actions/_update/<document_id>
{
"script": {
"source": "ctx._source.details += ' - Additional details'",
"lang": "painless"
}
}2. 데이터 삭제
Elasticsearch에서는 문서를 삭제할 때 delete API를 사용합니다.
특정 문서를 삭제하려면 문서 ID를 사용하여 삭제할 수 있습니다.
DELETE /user_actions/_doc/<document_id>3. 조건부 삭제
특정 조건을 만족하는 문서를 삭제하려면 delete_by_query API를 사용합니다.
특정 사용자 ID에 해당하는 모든 문서를 삭제합니다.
POST /user_actions/_delete_by_query
{
"query": {
"match": {
"user_id": "user123"
}
}
}4. 예제 전체 흐름
아래는 인덱스를 생성하고, 문서를 추가하고, 업데이트하고, 삭제하는 전체 예제입니다.
인덱스 생성 및 문서 추가
PUT /user_actions
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"user_id": {
"type": "keyword"
},
"action": {
"type": "text"
},
"details": {
"type": "text"
}
}
}
}
POST /user_actions/_doc/1
{
"timestamp": "2024-07-08T10:00:00Z",
"user_id": "user123",
"action": "login",
"details": "User logged in successfully"
}문서 업데이트
POST /user_actions/_update/1
{
"doc": {
"action": "logout"
}
}문서 삭제
DELETE /user_actions/_doc/15. 참고 사항
- 실시간성: Elasticsearch는 기본적으로 실시간으로 데이터를 검색할 수 있지만, 업데이트와 삭제는 내부적으로 배치 작업을 수행하여 반영되므로, 완벽한 실시간 반영이 보장되지는 않습니다.
- 성능 고려: 업데이트와 삭제 작업은 전체 인덱스의 재작성으로 이어질 수 있으므로, 빈번한 업데이트와 삭제 작업이 필요한 경우 Elasticsearch의 성능을 고려해야 합니다.
이와 같이 Elasticsearch에서도 RDBMS처럼 데이터의 업데이트와 삭제 작업을 수행할 수 있지만, 그 방식과 내부 작동 원리가 다르다는 점을 유의해야 합니다. 이를 적절히 활용하여 필요한 기능을 구현할 수 있습니다.




댓글