
Pandas는 Python에서 데이터 분석 및 조작을 위한 강력한 라이브러리입니다. 데이터 과학자, 분석가, 엔지니어들이 데이터를 효과적으로 처리하고 분석하는 데 널리 사용됩니다. Pandas는 특히 테이블 형식의 데이터를 다루는 데 유용하며, 엑셀 스프레드시트와 유사한 방식으로 데이터를 조작할 수 있습니다.
Pandas의 핵심 개념
- Series
- Pandas의 가장 기본적인 데이터 구조입니다. Series는 일련의 데이터를 담는 1차원 배열로, 각 데이터에 인덱스(레이블)가 붙어 있습니다.
- 예를 들어, 날짜별 주가 데이터가 Series에 저장될 수 있습니다.
이 코드는 날짜를 인덱스로 가지는 4개의 값(10, 20, 30, 40)을 가진 Series를 생성합니다.import pandas as pd # 간단한 Series 예제 data = pd.Series([10, 20, 30, 40], index=['2024-08-01', '2024-08-02', '2024-08-03', '2024-08-04']) print(data) - DataFrame
- Pandas에서 가장 많이 사용되는 데이터 구조입니다. DataFrame은 행과 열로 구성된 2차원 데이터 구조로, 각 열이 서로 다른 데이터 타입을 가질 수 있습니다.
- 엑셀의 시트와 유사한 형식이며, 각 열은 Series 객체로 표현됩니다.
이 코드는 이름, 나이, 도시 정보를 포함하는 DataFrame을 생성합니다.import pandas as pd # 간단한 DataFrame 예제 data = { 'Name': ['Alice', 'Bob', 'Charlie', 'David'], 'Age': [25, 30, 35, 40], 'City': ['New York', 'Los Angeles', 'Chicago', 'Houston'] } df = pd.DataFrame(data) print(df)
Pandas의 주요 기능
- 데이터 로드 및 저장
- CSV, Excel, SQL, JSON 등 다양한 파일 포맷에서 데이터를 로드하고 저장할 수 있습니다.
# CSV 파일에서 데이터 로드 df = pd.read_csv('data.csv') # DataFrame을 CSV 파일로 저장 df.to_csv('output.csv', index=False) - 데이터 필터링 및 정렬
- 특정 조건에 맞는 데이터를 필터링하거나, 열을 기준으로 데이터를 정렬할 수 있습니다.
# 나이가 30 이상인 사람 필터링 filtered_df = df[df['Age'] >= 30] # 나이 순으로 정렬 sorted_df = df.sort_values(by='Age') - 데이터 요약 및 집계
- 데이터를 그룹화하여 요약 통계를 계산할 수 있습니다. 예를 들어, 도시별 평균 나이를 계산할 수 있습니다.
# 도시별 평균 나이 계산 grouped_df = df.groupby('City')['Age'].mean() print(grouped_df) - 결측값 처리
- 데이터에 누락된 값이 있는 경우 이를 처리할 수 있습니다. 예를 들어, 결측값을 특정 값으로 채우거나 제거할 수 있습니다.
# 결측값을 0으로 채우기 df.fillna(0, inplace=True) # 결측값이 있는 행 제거 df.dropna(inplace=True) - 데이터 변환 및 조작
- 열 추가, 제거, 데이터 형식 변환 등 다양한 데이터 조작이 가능합니다.
# 새로운 열 추가 df['Salary'] = [50000, 60000, 70000, 80000] # Age 열의 값을 문자열로 변환 df['Age'] = df['Age'].astype(str)
Pandas의 장점
- 사용 용이성: 엑셀과 유사한 데이터 조작 방식으로, 파이썬을 처음 접하는 사용자도 쉽게 사용할 수 있습니다.
- 유연성: 데이터 구조(Series, DataFrame)가 매우 유연하여 다양한 형식의 데이터를 다룰 수 있습니다.
- 강력한 기능: 데이터를 로드, 저장, 필터링, 집계, 변환하는 데 필요한 모든 기능을 제공합니다.
- 대규모 데이터 처리: 대량의 데이터를 효율적으로 처리할 수 있으며, 복잡한 데이터 분석 작업을 간단한 코드로 수행할 수 있습니다.

Pandas는 데이터 분석에 있어 매우 강력한 도구이며, 데이터 전처리, 분석, 시각화 등의 다양한 작업을 효율적으로 수행할 수 있습니다. 데이터 분석에 pandas 모듈을 사용하는 간단한 예제로 웹사이트 방문자들의 유입처를 분석하여 각 유입처 별 방문자 수를 집계합니다. 가상의 데이터를 생성하여 진행합니다.
import pandas as pd
import numpy as np
# 가상의 데이터 생성
data = {
'Date': pd.date_range(start='2024-04-01', periods=100, freq='D'),
'Visitor_ID': np.random.randint(1, 1000, 100),
'Source': np.random.choice(['Google', 'Facebook', 'Direct', 'Newsletter', 'Bing'], 100)
}
# DataFrame 생성
df = pd.DataFrame(data)
# 데이터 확인
print(df.head())
# 각 유입처 별 방문자 수 집계
source_counts = df['Source'].value_counts()
# 집계 결과 출력
print(source_counts)- 데이터 생성: 날짜, 방문자 ID, 유입처를 포함하는 가상의 데이터를 생성합니다. 여기서 'Source'는 방문자가 웹사이트에 어떻게 도달했는지를 나타냅니다 (예: 구글, 페이스북 등).
- DataFrame 생성: pandas의
DataFrame을 사용하여 데이터를 정형화된 형태로 조작합니다. - 데이터 확인:
head()함수를 사용해 생성된 데이터의 첫 5행을 출력하여 데이터가 올바르게 생성되었는지 확인합니다. - 집계:
value_counts()함수를 사용하여 'Source' 열에 따라 데이터를 집계하고 각 유입처별 방문자 수를 계산합니다. - 결과 출력: 집계된 결과를 출력합니다.
이 코드는 실제 로우 데이터를 사용하는 경우 데이터 구조에 따라 약간의 조정이 필요할 수 있습니다. 데이터의 크기나 특성에 따라 성능 문제를 고려하여 적절한 데이터 처리 방법을 선택하는 것이 중요합니다.
보안 관리를 위한 데이터 분석 예제로, 웹사이트 로그 데이터를 사용하여 잠재적인 보안 위협을 탐지하는 과정입니다. 이 예제에서는 IP 주소별로 접근 빈도를 분석하고, 비정상적으로 높은 접근을 보이는 IP 주소를 식별합니다.
가상의 웹사이트 로그 데이터 생성 및 분석
import pandas as pd
import numpy as np
# 가상의 웹사이트 로그 데이터 생성
np.random.seed(42)
data = {
'Timestamp': pd.date_range(start='2024-04-01', periods=1000, freq='T'), # 1000분 간격 데이터
'IP_Address': np.random.choice(['192.168.1.1', '192.168.1.2', '192.168.1.3', '192.168.1.4', '203.0.113.1'], 1000),
'Request': np.random.choice(['GET', 'POST', 'PUT', 'DELETE'], 1000),
'URL': np.random.choice(['/home', '/login', '/signup', '/account', '/data'], 1000),
'Status_Code': np.random.choice([200, 404, 500, 403], 1000)
}
# DataFrame 생성
df = pd.DataFrame(data)
# 데이터 확인
print(df.head())
# IP 주소별 요청 수 집계
ip_counts = df['IP_Address'].value_counts()
# 집계 결과 출력
print(ip_counts)
# 비정상적인 접근 빈도를 보이는 IP 주소 탐지 (기준: 100회 이상 요청)
suspicious_ips = ip_counts[ip_counts > 100]
# 결과 출력
print("Suspicious IPs:")
print(suspicious_ips)- 데이터 생성
Timestamp: 로그 데이터의 타임스탬프입니다.IP_Address: 요청을 보낸 IP 주소입니다.Request: HTTP 요청 메서드(GET, POST, PUT, DELETE)입니다.URL: 요청된 URL 경로입니다.Status_Code: HTTP 응답 상태 코드입니다.
- DataFrame 생성: pandas의
DataFrame을 사용하여 로그 데이터를 생성하고 조작할 수 있도록 합니다. - 데이터 확인:
head()함수를 사용해 생성된 데이터의 첫 5행을 출력하여 데이터가 올바르게 생성되었는지 확인합니다. - IP 주소별 요청 수 집계:
value_counts()함수를 사용하여 'IP_Address' 열을 기준으로 요청 수를 집계합니다. - 비정상적인 접근 빈도를 보이는 IP 주소 탐지
ip_counts > 100조건을 사용하여 요청 수가 100회를 초과하는 IP 주소를 필터링합니다.- 이러한 IP 주소는 비정상적으로 높은 접근 빈도를 보일 수 있으며, 잠재적인 보안 위협으로 간주될 수 있습니다.
- 결과 출력: 비정상적으로 높은 접근 빈도를 보이는 IP 주소를 출력합니다.
- 시간대별 분석: 특정 시간대에 비정상적으로 많은 요청이 발생하는지 분석하여 DOS 공격을 탐지합니다.
- 상태 코드 분석: 403, 500과 같은 오류 상태 코드가 많이 발생하는 IP 주소를 탐지하여 잠재적인 공격을 확인합니다.
- URL 패턴 분석: 특정 URL 경로에 집중적으로 접근하는 IP 주소를 탐지하여 의심스러운 활동을 확인합니다.
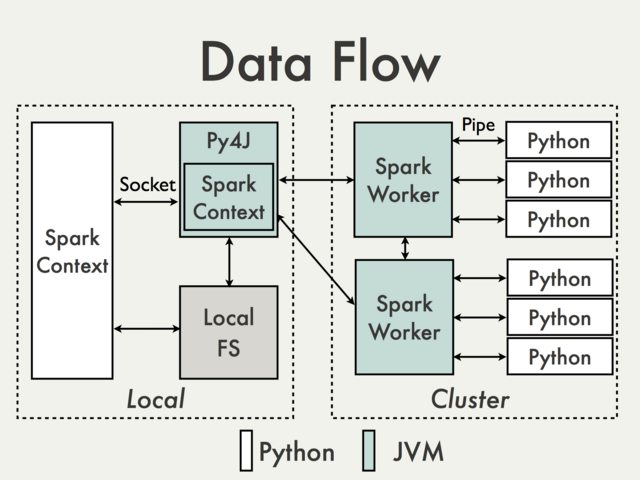
이와 같은 데이터 분석 방법을 통해 보안 관리에 필요한 정보를 얻고, 잠재적인 위협을 사전에 탐지하여 대응할 수 있습니다. Pandas와 유사한 PySpark는 둘 다 데이터 분석에 널리 사용되는 도구이지만, 사용 목적, 처리할 수 있는 데이터의 크기, 성능, 사용 용이성 등에서 차이가 있습니다. 아래에 두 도구를 여러 측면에서 비교합니다.
데이터 크기 처리 능력
- Pandas: 주로 단일 머신의 메모리 내에서 데이터를 처리합니다. 따라서 메모리 용량에 따라 처리할 수 있는 데이터 크기가 제한됩니다. 일반적으로 수백 메가바이트에서 몇 기가바이트 정도의 데이터를 처리하는 데 적합합니다.
- PySpark: Apache Spark의 Python API로, 클러스터 환경에서 분산 처리하여 대규모 데이터를 다룰 수 있습니다. 수 테라바이트 또는 페타바이트 규모의 데이터를 처리할 수 있으며, 여러 노드에서 병렬로 작업을 수행합니다.
성능
- Pandas: 데이터가 메모리에 적재된 상태에서 작업을 수행하므로 소규모 데이터에 대해서는 매우 빠르고 효율적입니다. 하지만 데이터 크기가 커질수록 메모리 한계로 인해 성능이 급격히 저하될 수 있습니다.
- PySpark: 분산 처리 덕분에 매우 큰 데이터셋을 효과적으로 처리할 수 있으며, 대규모 데이터를 처리하는 데 있어서 훨씬 높은 성능을 제공합니다. 특히, PySpark는 하둡 분산 파일 시스템(HDFS)과 통합하여 빅데이터 처리에 강점을 가지고 있습니다.
데이터 모델
- Pandas: 단일 노드에서 동작하며, 데이터프레임은 행과 열로 구성된 테이블 형식의 데이터 구조를 가지고 있습니다. 이는 엑셀 시트와 유사하며, 사용자가 직관적으로 데이터를 다룰 수 있습니다.
- PySpark: PySpark의 DataFrame은 SQL 테이블과 유사한 데이터 구조를 가지고 있으며, Spark SQL을 통해 SQL 쿼리로 데이터를 조작할 수 있습니다. PySpark의 DataFrame은 RDD(Resilient Distributed Dataset) 위에 구축되어 있어 분산 데이터 처리가 가능합니다.
사용 용이성
- Pandas: Python을 사용한 데이터 분석에서 가장 쉽게 접근할 수 있는 도구 중 하나입니다. API가 직관적이고 사용하기 쉬워, 데이터를 빠르게 조작하고 분석할 수 있습니다. 소규모 데이터 분석 및 시각화에 적합합니다.
- PySpark: Pandas보다는 다소 복잡할 수 있으며, 분산 처리와 빅데이터를 다루기 위한 추가적인 학습이 필요합니다. 하지만 대규모 데이터를 처리하는 데 필수적인 도구입니다. 클러스터 관리, 작업 분할 및 병합 등의 개념을 이해해야 합니다.
배포 및 확장성
- Pandas: 로컬 환경에서 실행되는 코드로, 스크립트 또는 Jupyter Notebook에서 쉽게 사용할 수 있습니다. 그러나 데이터를 확장하려면 대체 기술이 필요할 수 있습니다.
- PySpark: 클러스터 환경에서 실행되며, 스케일링이 용이합니다. AWS EMR, Google Dataproc, Databricks와 같은 클라우드 플랫폼에서 쉽게 배포할 수 있으며, 대규모 데이터 분석 작업을 처리할 수 있습니다.
통합 및 호환성
- Pandas: 다양한 파일 포맷(CSV, Excel, SQL 데이터베이스, JSON 등)을 읽고 쓸 수 있으며, Matplotlib, Seaborn과 같은 데이터 시각화 도구와 쉽게 통합됩니다. 머신러닝 라이브러리인 Scikit-learn과도 자연스럽게 연동됩니다.
- PySpark: Hadoop, Hive, HDFS, Cassandra, HBase 등 다양한 빅데이터 생태계 도구와 통합됩니다. PySpark는 MLib를 통해 대규모 데이터에 대한 머신러닝 모델을 구축할 수 있습니다.
커뮤니티 및 지원
- Pandas: 매우 큰 사용자 기반과 풍부한 문서, 예제 코드가 제공됩니다. 사용자 포럼과 GitHub에서 활발한 지원을 받을 수 있습니다.
- PySpark: Spark는 오픈 소스 빅데이터 프로젝트 중 하나로, 많은 기업과 커뮤니티에서 사용됩니다. 다만, Pandas보다는 진입 장벽이 높을 수 있습니다.
실제 사용 예
- Pandas: 금융 데이터 분석, 웹 스크래핑 후 데이터 처리, 소규모 로그 파일 분석, 데이터 전처리 및 EDA(탐색적 데이터 분석) 작업.
- PySpark: 로그 데이터의 실시간 처리, 대규모 데이터셋의 ETL 작업, 분산된 환경에서의 데이터 분석 및 머신러닝 모델 구축.
Pandas와 PySpark 중 어떤 것을 사용할지는 주로 분석하려는 데이터의 크기와 분석 목적에 따라 결정됩니다. 작은 데이터셋을 다룰 때는 Pandas가 적합하며, 대규모 데이터셋을 처리해야 하는 경우 PySpark가 더 적합합니다. 아래는 Pandas와 PySpark의 주요 특징을 비교한 표입니다.
| 특징 | Pandas | PySpark |
|---|---|---|
| 데이터 크기 처리 능력 | 주로 메모리 내 데이터 처리 (수 MB ~ GB 수준) | 분산 처리 가능 (수 TB ~ PB 규모의 대규모 데이터) |
| 성능 | 메모리 내 연산으로 소규모 데이터에 빠름 | 분산 처리로 대규모 데이터에 대해 높은 성능 제공 |
| 데이터 모델 | 2차원 DataFrame (엑셀 시트와 유사) | 분산 DataFrame (SQL 테이블과 유사) |
| 사용 용이성 | 직관적이고 간단함, 데이터 분석 초급자에게 적합 | 분산 처리 및 클러스터 관리 이해 필요, 복잡할 수 있음 |
| 배포 및 확장성 | 로컬 환경에서 실행, 대규모 데이터 처리 한계 | 클러스터 환경에서 쉽게 스케일링 및 배포 가능 |
| 통합 및 호환성 | CSV, Excel, SQL 등 다양한 파일 포맷 지원 | Hadoop, Hive, HDFS 등 빅데이터 생태계와 통합 |
| 커뮤니티 및 지원 | 풍부한 문서와 예제, 큰 사용자 커뮤니티 | Spark 기반으로 활발한 커뮤니티, 다소 높은 진입 장벽 |
| 실제 사용 예 | 소규모 데이터 분석, EDA, 웹 스크래핑 후 데이터 처리 | 대규모 데이터 ETL, 실시간 로그 처리, 빅데이터 분석 |
이 표를 통해 Pandas와 PySpark의 특징과 용도를 한눈에 비교할 수 있습니다. 데이터를 처리하는 환경과 요구 사항에 따라 적합한 도구를 선택하는 데 도움이 될 것입니다.




댓글