728x90
1️⃣ 인공지능 프라이버시 리스크 진단 및 인증 방안
✔️ 목적
- AI 모델이 초래할 수 있는 프라이버시 리스크의 체계적 진단·평가 기준 수립
- 기존 ‘AI 프라이버시 리스크 관리 모델’(2023년 12월 발표)의 후속 작업
✔️ 제언 주요 내용 (김병필 카이스트 교수 발표)
- 산업계·학계 중심의 진단 기술 및 사례 분석
- 진단 프레임워크 설계 방안: AI 시스템의 리스크를 구체적으로 측정하고 인증할 수 있는 체계 구축 필요
- 기술 발전과 개인정보 보호의 균형을 위한 사전적‧예방적 관리 체계 마련
2️⃣ 생성형 인공지능 개발·활용을 위한 개인정보 처리 안내서(안)
✔️ 발표 배경
- 생성형 AI 기술의 급속한 확산에 따라, 개인정보 처리 법적 불확실성과 기술적 리스크 증가
- 기존 법체계로는 복잡한 데이터 흐름, 처리 방식 대응에 한계 발생
✔️ 주요 내용
- AI 수명주기 단계별 개인정보 처리 고려사항
- 목표 설정 → 전략 수립 → 시스템 적용 및 운영 → AI 학습 및 개발
- 각 단계에서의 적법성‧안전성 확보 기준 명시
- 실무 적용성 강화
- 법령 안내, 집행 사례, 규제샌드박스 경험 포함
- 미국·영국·EU의 정책 흐름 반영
- 예정 사항: 시민단체와 전문가 의견을 반영하여 7월 말까지 최종 안내서 마련
🔎 페이지 3 시각 자료 요약
<생성형 인공지능 개발‧활용 단계별 고려사항>
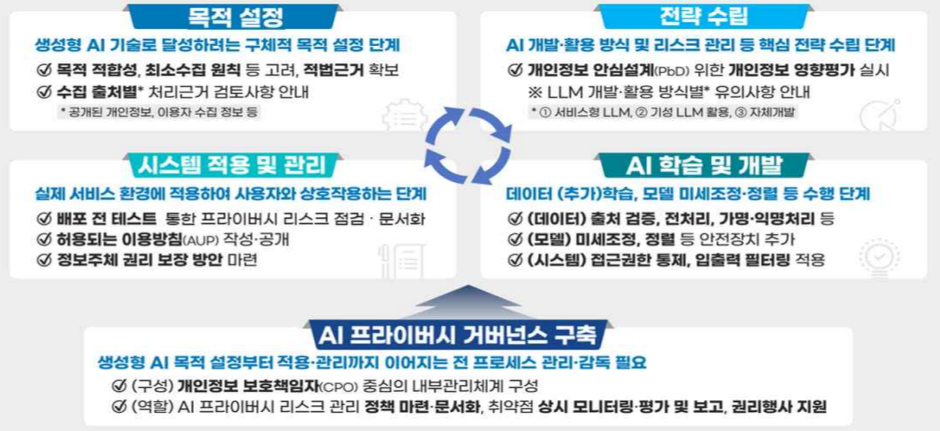
- 목적 설정: 설명책임 확보, 데이터 처리 목적 명확화
- 전략 수립: 활용방식에 따라 처리계획 수립 (예: 학습, 파인튜닝 등)
- 시스템 적용: 시스템 설계 시 AI 프라이버시 원칙 내재화
- AI 학습 및 개발: 데이터 정제·분리, 민감정보 제거
- AI 프라이버시 거버넌스: 개인정보 보호책임자(CPO), 내부관리계획, 리스크 기반 모니터링
🗣️ 모두발언 요지 (고학수 위원장)
- 프라이버시 리스크 예방 및 제도적 가드레일 구축이 신뢰할 수 있는 AI 발전의 필수조건임을 강조
- “AI 혁신을 위한 프라이버시”와 “프라이버시를 위한 AI 혁신”이 상호 발전적 관계에 놓여야 함
- 생성형 AI의 빠른 확산에 대응하기 위한 실무 지침 마련은 법적 불확실성 해소와 국민 신뢰 회복에 기여할 수 있음
- 향후 방향
- 개인정보 법제 정비
- 고가치 데이터의 안전하고 책임감 있는 활용
- 공공·민간 협업 기반 강화
300x250
정책 및 기술적 함의
개인정보 보호 가이드라인 적용 포인트
| 적용 대상 | 점검 포인트 |
|---|---|
| 생성형 AI 개발팀 | 수명주기 단계별 개인정보 처리 설계 여부, 적법성 확보 근거, 프라이버시 강화 설계 |
| 기업 법무팀 | AI 개인정보 처리의 법적 정당성 평가, 기존 개인정보 보호법과의 정합성 검토 |
| 보안 담당자 | 리스크 기반 점검 항목 수립, 민감정보 노출 여부, 처리흐름에 따른 보안제어 이행 여부 |
| 거버넌스 관리자 | CPO 지정 여부, 내부관리계획 운영, 외부 감사 및 점검 체계 수립 |
생성형 AI 개발·활용을 위한 개인정보 처리 기준 안내서
1. 배경 및 목적
정책 배경
- ChatGPT, LLaMA 등 LLM 기반 생성형 AI의 확산으로 개인정보의 대규모 수집·이용 문제가 부각.
- 특히 의료, 공공, 금융 분야에 축적된 고품질 데이터가 LLM 학습 데이터로 활용되면서 프라이버시 침해 우려 증가.
- 산업계에서는 법 적용의 불확실성 해소와 실무 활용 가능한 기준 마련을 지속적으로 요구.
안내서의 주요 목적
- 생성형 AI 생애주기(목적 설정 → 전략 수립 → 학습·개발 → 시스템 적용·관리) 전반에서 개인정보 처리의 적법성·안전성 확보 기준 제시.
- 사업자들의 자율적인 법 준수 역량 강화와 법적 예측 가능성 제공.
- 생성형 AI 활용 유형(서비스형 LLM, 기성 LLM 활용, 자체개발)에 따라 구체적 안전조치와 법적 기준 안내.

2. 주요 내용 요약
① 생애주기 단계별 기준
| 단계 | 주요 내용 | 고려사항 |
|---|---|---|
| 1. 목적 설정 | 개인정보 처리 목적 명확화 | 수집 출처별 적법근거 (공개 정보, 사용자 정보 등) 검토 |
| 2. 전략 수립 | AI 개발 방식 결정 (서비스형 / 기성 LLM / 자체개발) | PbD 적용, 영향평가, 개발 전략별 리스크 점검 |
| 3. AI 학습 및 개발 | 데이터 수집·전처리, 모델 정렬, 시스템 보호조치 | 데이터 오염 방지, 미세조정·정렬, PET 기술, feedback loop 내재화 |
| 4. 시스템 적용 및 관리 | 실제 운영환경 적용, 권리보장 | 배포 전 테스트, AUP 설정, 정보주체 권리보장 절차 마련 |
| 5. 거버넌스 구축 | 전사적 개인정보 보호 체계 수립 | CPO 중심의 거버넌스, 레드팀 운영, 최고위 보고 체계 구축 |
② 활용 유형별 분류 및 가이드
| 분류 | 설명 | 예시 |
|---|---|---|
| 서비스형 LLM | 상용 API 연계 (예: ChatGPT API) | 계약서 기반으로 재학습 금지, 데이터 보관 정책 명확화 필요 |
| 기성 LLM 활용 | 오픈소스 LLM 다운로드 후 추가 학습 | 학습 데이터 출처 확인, 모델카드·라이선스 검토 |
| 자체개발 | LLM 또는 SLM 직접 개발 | 전 과정 통제 가능, 비용·리소스 고위험, 자체 R&D 체계 필요 |
※ 서비스형 LLM 활용 시 ‘기업용 라이선스(Enterprise API)’ 사용을 통해 개인정보 보호 강화 권장됨
3. 법적 쟁점별 고려사항
수집 목적 및 적법 근거 구분
| 유형 | 설명 | 적용 법 조항 |
|---|---|---|
| 공개 데이터 | 공개된 개인정보 수집·활용 | 정당한 이익 조항(제15조 1항 6호) |
| 사용자 데이터 | 기존 이용자 정보의 재사용 | 목적 내 이용 / 추가적 이용(제15조 3항) |
| 별도 목적 | 신규 서비스 개발 | 동의, 가명·익명 처리, 제18조 근거 등 필요 |
※ 적절한 경우 규제 샌드박스 활용 가능
4. 기술·보안 조치 가이드
데이터 수집 및 전처리
- 데이터 오염(poisoning) 방지 위한 출처 검증, 가명·익명 처리, PET 기술 적용
- robots.txt, CAPTCHA 등 학습거부 표시 콘텐츠는 제외
모델 보호
- 암기, 정렬로 인한 개인정보 노출 방지 위해 SFT, RLHF, DPO, GRPO 적용
- 차분 프라이버시 기반 학습(DP-SGD), 지식증류 기반 언러닝 기술 활용 가능
시스템 보안
- API 접근제어, 입출력 필터링 적용
- AI 프롬프트 입력 단계부터 필터링 적용 필요 (예: 주민등록번호, 민감정보 차단)

5. 정보주체 권리보장 및 투명성
| 항목 | 권장 사항 |
|---|---|
| 🔹 AUP (허용된 사용 정책) | 사용자에게 명시적으로 안내, 예: 민감정보 입력 금지, 악용 방지 |
| 🔹 옵트아웃 기능 | 데이터 학습 거부 기능 UI 제공 및 재고지 절차 포함 |
| 🔹 삭제·정정·열람권 | 기술적으로 불가능한 경우, 대체수단(예: 출력 필터링)으로 보완 |
| 🔹 자동화 결정 | 정보주체의 거부권, 설명요구권, 인적 검토 보장 (법 제37조의2) |
6. 거버넌스 및 책임체계
- CPO 중심의 내부 관리 체계 필수
- AI 기획 초기부터 CPO, CISO, CAIO 간 협업 필요
- 레드팀 운영, 안전성 테스트 및 평가 프레임워크 도입 권장
- 예시: HarmBench, JailBreakBench 등 공개 벤치마크 사용
유형별 체크리스트
🧾 모델개발자 vs 모델이용자별 프라이버시 고려사항은 [붙임 표]에서 구체적으로 구분 제시됨.
[별첨1] 생성형 인공지능(AI) 개발 활용을 위한 개인정보 처리 안내서 발표자료_F.pdf
3.51MB
[별첨2] 생성형 인공지능(AI) 개발 활용을 위한 개인정보 처리 안내서.pdf
1.65MB
출처 : 개인정보보호위원회
향후 계획
- 본 안내서는 생성형 AI 기술의 혁신성과 개인정보 보호 간 균형을 추구하는 가이드라인의 기준선 역할 수행
- 향후 기술 발전 및 국내외 정책 변화에 맞춰 지속적 개정 예정
- 민관 협력을 통한 자율 규제, 선제적 대응 역량 강화가 필수
728x90
그리드형(광고전용)




댓글