 ESM(enterprise security management)
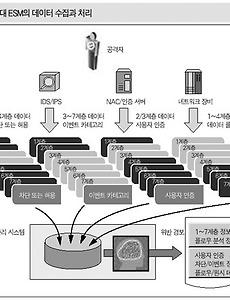
방화벽, 침입 탐지 시스템, 가상 사설망 등의 보안 솔루션을 하나로 모은 통합 보안 관리 시스템. 최근 기업 보안 관리(ESM)는 통합 관리 수준에서 벗어나 시스템 자원 관리(SMS), 망 관리 시스템(NMS) 등 기업 자원 관리 시스템까지 확대, 개발되고 있다. ESM은 기업들이 서로 다른 기종의 보안 솔루션 설치에 따른 중복 투자, 자원 낭비를 줄일 수 있으며, 솔루션 간 상호 연동을 통해 전체 정보 통신 시스템에 대한 보안 정책을 수립할 수 있다는 장점이 있다. ESM의 등장배경 보안의 개념은 처음에는 침입차단시스템(Firewall) 수준을 넘지 못했지만 최근의 보안은 침입차단 (방화벽), 가상사설망 (VPN), 침입탐지(IDS), 시스템 보안, 인증, 안티 바이러스, 데이터 백업에 이르기까지 전문..
2009. 6. 11.
ESM(enterprise security management)
방화벽, 침입 탐지 시스템, 가상 사설망 등의 보안 솔루션을 하나로 모은 통합 보안 관리 시스템. 최근 기업 보안 관리(ESM)는 통합 관리 수준에서 벗어나 시스템 자원 관리(SMS), 망 관리 시스템(NMS) 등 기업 자원 관리 시스템까지 확대, 개발되고 있다. ESM은 기업들이 서로 다른 기종의 보안 솔루션 설치에 따른 중복 투자, 자원 낭비를 줄일 수 있으며, 솔루션 간 상호 연동을 통해 전체 정보 통신 시스템에 대한 보안 정책을 수립할 수 있다는 장점이 있다. ESM의 등장배경 보안의 개념은 처음에는 침입차단시스템(Firewall) 수준을 넘지 못했지만 최근의 보안은 침입차단 (방화벽), 가상사설망 (VPN), 침입탐지(IDS), 시스템 보안, 인증, 안티 바이러스, 데이터 백업에 이르기까지 전문..
2009. 6. 11.

