728x90
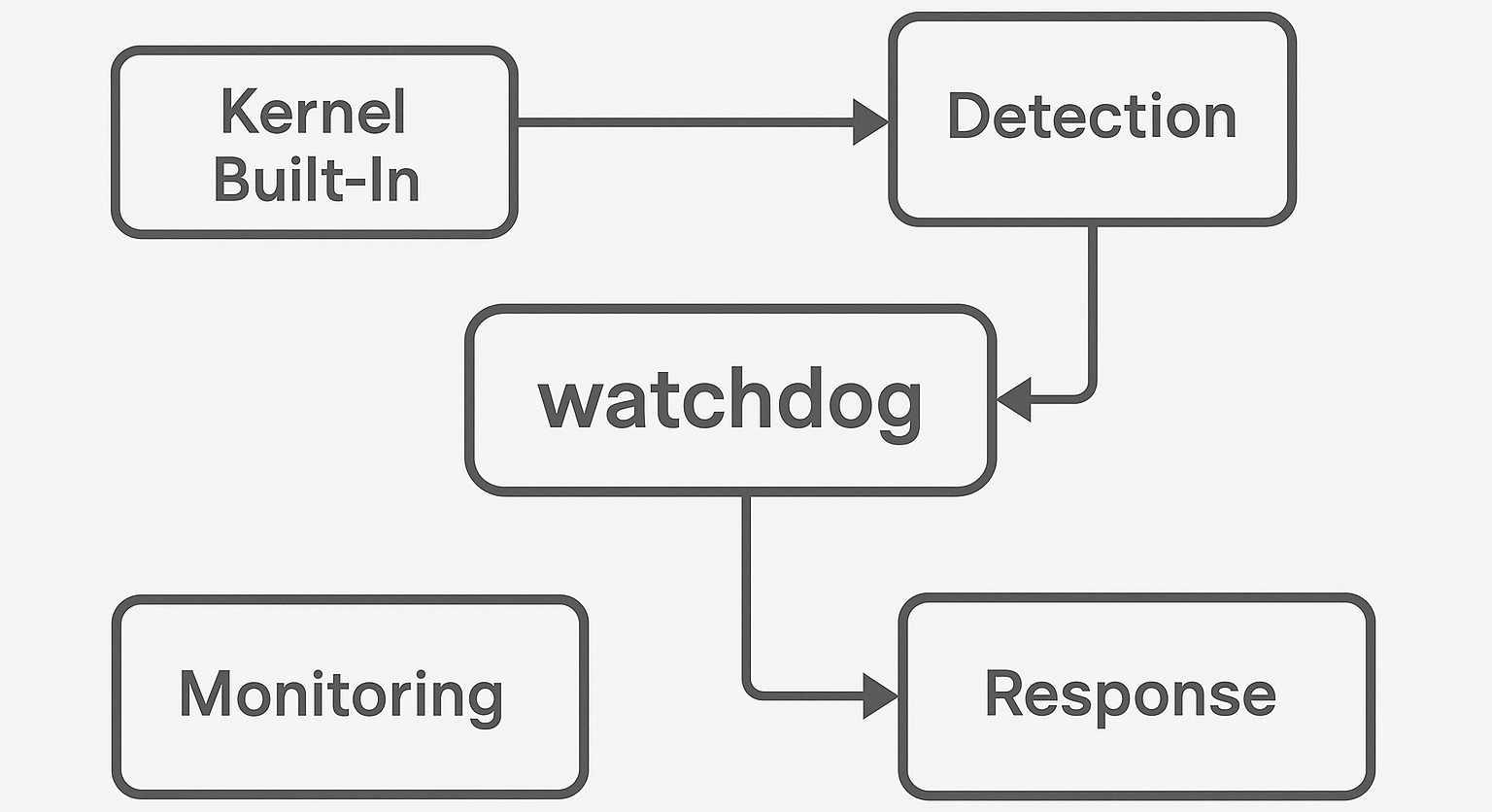
Watchdog가 뭔가요?
- 커널 내장 감시자
- 각 CPU 코어가 정기적으로 “살아있다(heartbeat)” 신호를 내야 합니다.
- 일정 시간 동안 응답이 없으면 락업(lockup) 으로 판단하고 커널 로그에 경고를 남깁니다.
- 종류 요약
- Soft lockup: 커널/프로세스가 오랫동안 스케줄러에서 빠져나오지 못함
(예: 무한 루프, 긴 비마스킹 구간, 드라이버 버그, 과도한 busy-wait) - Hard lockup: NMI(Non-Maskable Interrupt) 수준에서도 CPU가 완전 멈춤 (하드웨어/커널 심각 문제)
- Hung task: 커널이 보기에 태스크가 너무 오래 깨어있지 못함(대기/블로킹) — 별도 감지기
- Soft lockup: 커널/프로세스가 오랫동안 스케줄러에서 빠져나오지 못함
- 패키지와의 차이
- 커널 감지기(지금 로그의 주인공): 기본 내장, 로그 남김/패닉 유도
- watchdog 데몬(패키지):
/dev/watchdog장치에 주기적 “핑” → 응답 없으면 자동 재부팅 등 수행
(원하면sudo apt install watchdog으로 별도 운영 가능)
탐지 기준(Threshold)과 핵심 파라미터
- 현재 값 확인
# 락업 감지 on/off cat /proc/sys/kernel/watchdog # soft/hard lockup 감지 윈도(초) - 보통 10~20초 범위 cat /proc/sys/kernel/watchdog_thresh # 헝 태스크(hung task) 타임아웃(초) - 기본 120초가 흔함 cat /proc/sys/kernel/hung_task_timeout_secs # NMI 워치독 (하드 락업) on/off cat /proc/sys/kernel/nmi_watchdog - 민감도 조정(예: VM에서 false positive 완화)
# 일시 적용 sudo sysctl -w kernel.watchdog=1 sudo sysctl -w kernel.watchdog_thresh=60 # soft/hard lockup 감지 윈도 확대 sudo sysctl -w kernel.hung_task_timeout_secs=300 # 헝 태스크 감지 여유 # 영구 적용 (예: /etc/sysctl.d/99-watchdog.conf) sudo tee /etc/sysctl.d/99-watchdog.conf <<'EOF' kernel.watchdog=1 kernel.watchdog_thresh=60 kernel.hung_task_timeout_secs=300 kernel.nmi_watchdog=1 EOF sudo sysctl --system - 패닉/재부팅 정책(고가용/어플라이언스에 유용)
- 커널 부트 파라미터(예: GRUB):
softlockup_panic=1,hardlockup_panic=1,hung_task_panic=1 - 재부팅 통해 빠른 자가복구가 필요한 장비에만 신중히 사용하세요.
- 커널 부트 파라미터(예: GRUB):
예시 로그 메시지 읽는 법(해석)
watchdog: BUG: soft lockup - CPU#0 stuck for 487s! [dockerd:1813]
→ CPU#0에서 dockerd(PID=1813) 가 487초간 스케줄러에 돌아오지 못함(사실상 바쁜 무한 루프/긴 블로킹).watchdog: BUG: soft lockup - CPU#1 stuck for 487s! [packetbeat:2791]
→ packetbeat 가 원인 축으로 의심.kworker/1:3
→ 커널 워커 스레드. 드라이버/블록/네트워크/파일시스템 경로 문제일 수 있음.
보안·운영 관점 모니터링 설계(Elastic/Wazuh/시스템 공통)
- 수집 포인트
dmesg,/var/log/kern.log,/var/log/syslog(Ubuntu는 journald 통합인 경우journalctl -k)- 패턴
watchdog: BUG: soft lockup - CPU#NMI watchdog: Watchdog detected hard LOCKUPINFO: task ... blocked for more than ... seconds(hung task)
- 운영 대시보드/알림
- Kibana KQL 예시
message : ("watchdog: BUG: soft lockup*" or "NMI watchdog: Watchdog detected hard LOCKUP*" or "INFO: task * blocked for more than * seconds*") - 심각도 등급 예시
hard lockup≥ 1회 → Criticalsoft lockup연속 3회/1시간 또는stuck > 120s→ Majorhung task5회/1시간 → Minor~Major(환경별 조정)
- Kibana KQL 예시
- Wazuh 규칙(간단 예시)
- Filebeat/Journalbeat 또는 Wazuh agent로 커널 로그 수집 → SIEM 경고/Slack 연동
<!-- /var/ossec/etc/rules/local_rules.xml --> <rule id="920100" level="8"> <if_log_contains>watchdog: BUG: soft lockup</if_log_contains> <description>Linux soft lockup detected</description> <group>system,availability,watchdog,</group> </rule> <rule id="920101" level="12"> <if_log_contains>NMI watchdog: Watchdog detected hard LOCKUP</if_log_contains> <description>Linux hard lockup detected</description> <group>system,availability,watchdog,</group> </rule> <rule id="920102" level="7"> <if_log_contains>INFO: task</if_log_contains> <if_log_contains>blocked for more than</if_log_contains> <description>Linux hung task detected</description> <group>system,availability,watchdog,</group> </rule>
VirtualBox + Ubuntu 환경 최적화(재발 방지)
- 호스트/게스트 리소스
- CPU 코어 2개 이상 할당, Execution cap 100%
- 메모리 여유(스왑 포함) 확보
- 호스트 절전/절전모드 중단(게스트 시간이 멈추면 false positive↑)
- VirtualBox VM 설정 권장
- System → Motherboard: I/O APIC 활성화
- System → Processor: PAE/NX 활성화, 코어 수 2+
- Acceleration: VT-x/AMD-V & Nested Paging 활성화
- Paravirtualization Interface: KVM (리눅스 게스트에 보편적)
- 게스트 커널 파라미터
- 과도 경고 시
kernel.watchdog_thresh=60처럼 여유 확대 - I/O 병목(디스크/네트워크) 튜닝: 디스크 캐시/호스트 I/O 스케줄러 확인
- 과도 경고 시
실무 트러블슈팅 체크리스트(명령/절차)
- 증상 캡처
dmesg -T | egrep -i "watchdog|lockup|hung task|nmi" journalctl -k -S -2h | egrep -i "watchdog|lockup|hung task|nmi" - 가해자 프로세스 파악
# 예: dockerd PID=1813라면 top -H -p 1813 ps -Tp 1813 sudo strace -p 1813 -f -tt -o /tmp/dockerd.strace & sleep 10; sudo kill %1 sudo cat /proc/1813/stack # 커널 스택 힌트(커널 진입 경로 파악) - 시스템 전체 관찰
vmstat 1 10 pidstat -u -r -d 1 10 iostat -xz 1 5 mpstat -P ALL 1 5 - 핫스팟 분석(perf)
sudo apt-get install -y linux-tools-$(uname -r) sudo perf top # 실시간 핫함수 sudo perf record -g -- sleep 10 && sudo perf report - 커널 SysRq 덤프(매우 유용)
# SysRq 활성화 echo 1 | sudo tee /proc/sys/kernel/sysrq # 잠긴 태스크 스택 덤프 echo w | sudo tee /proc/sysrq-trigger # 모든 태스크 백트레이스 echo t | sudo tee /proc/sysrq-trigger - Docker/컨테이너 각론
- 컨테이너에 CPU 제한(quota) 걸려 과도 스로틀?
docker inspect <container> | jq '.[0].HostConfig.NanoCpus, .[0].HostConfig.CpuQuota' - cgroup 사용률
systemd-cgtop - 커널/네트워크 경로 이슈(예: packetbeat): 버전 업데이트, pcap 모드/af_packet 설정 점검, 드롭/리트라이나 DNS 역조회 끄기 등 튜닝
- 컨테이너에 CPU 제한(quota) 걸려 과도 스로틀?
300x250
대응 플레이북
- 즉각 조치
- 동일 호스트에서 hard lockup 발생 → 장애 채널 알림 + 장애 선언
- soft lockup 단발성 → 로그/지표 수집 후 관찰
- 연속 발생/장시간(>120s) → 서비스 영향 평가 및 롤백/재시작/VM 재배치 고려
- 근본 원인(예시 분류)
- 애플리케이션 루프/스핀락: 해당 버전 핫픽스/롤백
- 드라이버/커널 버그: HWE 커널/업스트림 수정 적용
- 가상화 스케줄링 지연: VM 리소스 상향, 호스트 부하 분산
- I/O 병목: 디스크/네트워크 튜닝, 큐 사이즈/IRQ 밸런싱
- 재발 방지
- VM/노드별
kernel.watchdog_thresh환경 표준화(예: 베어메탈 20, VM 60) - 시나리오 모니터링 규칙(섹션 4의 KQL/Wazuh 룰) 운영
- 장애 Postmortem에 perf/SysRq 덤프 첨부 의무화
- VM/노드별

systemd/하드웨어 Watchdog와의 관계
- systemd 서비스 Watchdog
- 유닛 파일에
WatchdogSec=30s→ 서비스가systemd-notify WATCHDOG=1주기 핑
핑이 끊기면 systemd가 서비스 재시작.
[Service] Type=notify WatchdogSec=30s ExecStart=/usr/local/bin/myservice- 애플리케이션에
sd_notify통합 필요.
- 유닛 파일에
- 하드웨어 Watchdog(선택)
/dev/watchdog드라이버(iTCO_wdt 등) +watchdog데몬- 커널이 멈추면 하드웨어가 강제 재부팅 — 산업/어플라이언스에 유용.
내부 사용자 가이드(요약 배포용)
- 증상 신고 템플릿
- 발생 시간 / 호스트명 / 게스트 종류(VM/베어메탈) / 메시지 전문 / 영향 범위
- 현장 점검 5분 루틴
journalctl -k -S -1h | egrep -i "watchdog|lockup|hung"- 문제 PID 상위 CPU 스레드:
top -H -p <PID> - SysRq 덤프:
echo w > /proc/sysrq-trigger; echo t > /proc/sysrq-trigger perf top30초 관찰 후 종료
- 시스템 튜닝 체크
- VM: 코어≥2, Execution cap 100%, Paravirtualization=KVM
- sysctl:
kernel.watchdog_thresh=60(가상),hung_task_timeout_secs=300
질문 로그에 대한 즉시 권고
- 단기
- VirtualBox VM에 코어 2+, Paravirt=KVM, VT-x/AMD-V & Nested Paging 켜기
- 아래 적용 후 경과 관찰
sudo sysctl -w kernel.watchdog_thresh=60 sudo sysctl -w kernel.hung_task_timeout_secs=300 - 문제 프로세스별 단기 조치
(dockerd 영향 크면), packetbeat는 버전 업데이트/설정 확인 후 재시작systemctl restart docker
- 중기
- 커널/가상화 드라이버 업데이트(게스트 확장팩 포함)
- Kibana/Wazuh 룰 배포 → 재발 시 즉시 알림
- 장기
- 반복 시 perf + SysRq 덤프로 근본원인 축적
- 필요 시 하드웨어 watchdog + 자동 재부팅 정책 검토(중요 노드)
728x90
그리드형(광고전용)




댓글