Claude SDK 자체도 비동기(async) 처리나 병렬 요청 구조를 지원하는 형태로 사용할 수 있어서, 동시에 여러 요청을 처리하는 멀티 처리 구조를 만들 수 있습니다.
다만 여기서 구분해야 하는 게 있습니다.
- Claude SDK 자체의 동시성(concurrency)
- 실제 모델 API의 rate limit / throughput 제한
- 애플리케이션 서버 구조
- Streaming 처리 여부
- Context isolation 문제
이걸 각각 나눠서 봐야 합니다.
기본적으로 가능한 구조
대표적으로 아래 형태들이 가능합니다.
- asyncio 기반 비동기 처리
- ThreadPool 기반 병렬 처리
- multiprocessing 기반 프로세스 분리
- FastAPI/Uvicorn/Gunicorn 기반 동시 API 처리
- Queue 기반 Worker 처리
- Kafka/RabbitMQ 기반 비동기 AI Worker
즉
여러 사용자 요청
↓
API 서버(FastAPI 등)
↓
Claude SDK 병렬 호출
↓
동시에 Claude 응답 처리구조가 가능합니다.
Python Async 방식
Claude SDK를 async로 호출하면 가장 효율적입니다.
예시
import asyncio
from anthropic import AsyncAnthropic
client = AsyncAnthropic(
api_key="YOUR_API_KEY"
)
async def ask_claude(prompt):
response = await client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
return response.content[0].text
async def main():
tasks = [
ask_claude("보안 로그 분석해줘"),
ask_claude("악성코드 특징 정리"),
ask_claude("WAF 정책 추천")
]
results = await asyncio.gather(*tasks)
for r in results:
print(r)
asyncio.run(main())이렇게 하면 동시에 여러 Claude 요청을 날립니다.
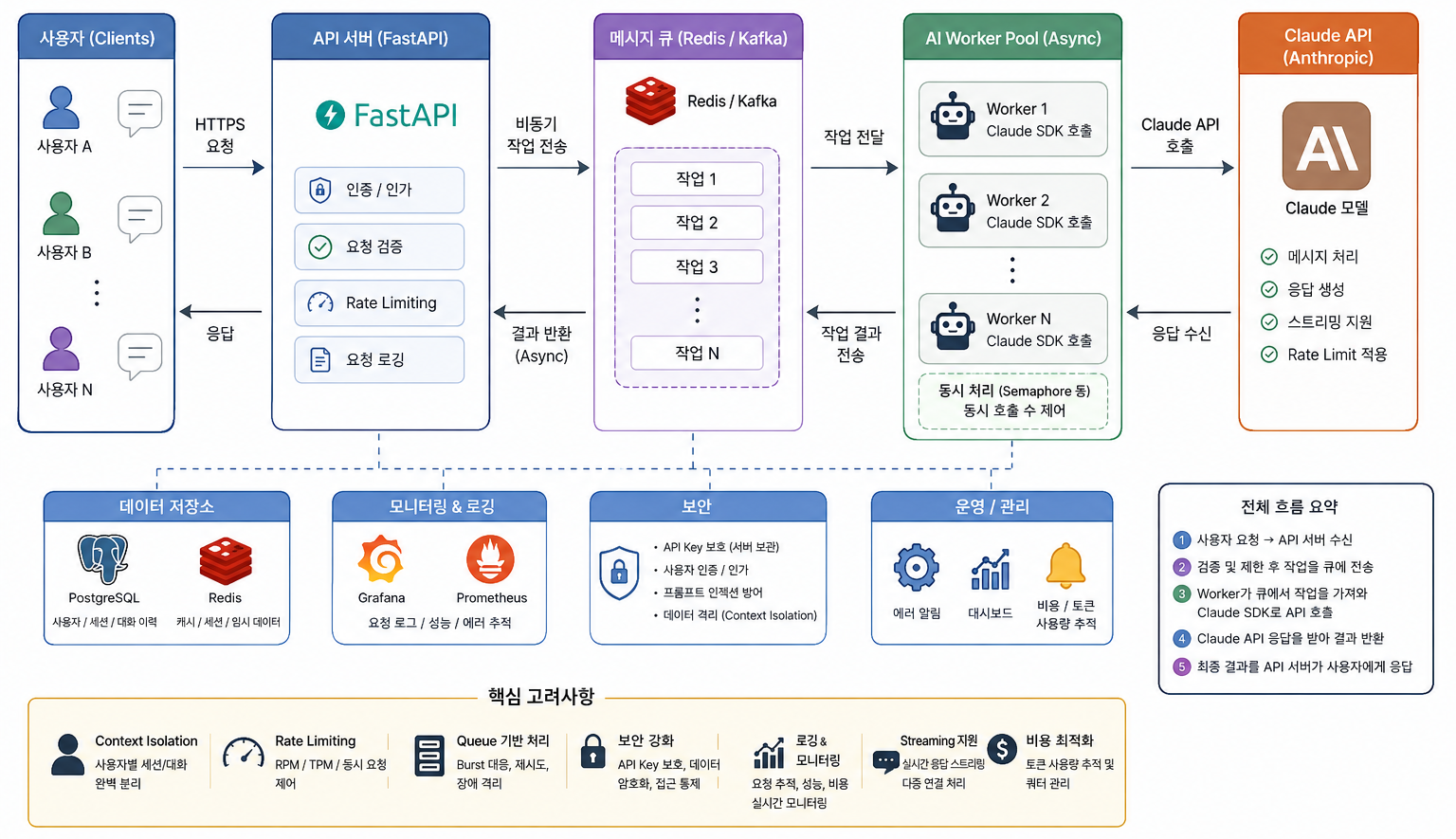
실제 운영 환경 구조
실제 서비스에서는 보통 이렇게 갑니다.
[사용자들]
↓
NGINX / LB
↓
FastAPI
↓
Async Worker
↓
Claude SDKFastAPI 예시
from fastapi import FastAPI
from anthropic import AsyncAnthropic
app = FastAPI()
client = AsyncAnthropic(
api_key="KEY"
)
@app.post("/chat")
async def chat(req: dict):
response = await client.messages.create(
model="claude-sonnet-4",
max_tokens=500,
messages=[
{
"role": "user",
"content": req["prompt"]
}
]
)
return {
"result": response.content[0].text
}이 경우 FastAPI 자체가 async 기반이라 동시 요청 처리가 가능합니다.
중요한 문제: Rate Limit
실제로 가장 먼저 걸리는 건 Claude SDK가 아니라 API 제한입니다.
Anthropic API는 보통
- RPM(Requests Per Minute)
- TPM(Tokens Per Minute)
- Concurrent Requests
제한이 존재합니다.
예를 들어 동시에 100명 요청이 들어오면
사용자 100명
→ SDK는 처리 가능
→ 하지만 API limit 초과 가능상황이 됩니다.
Semaphore 제한
semaphore = asyncio.Semaphore(5)
async def ask(prompt):
async with semaphore:
return await client.messages.create(...)이렇게 하면 최대 5개만 동시에 Claude 호출.
Queue 기반 권장
대규모 서비스에서는 Queue가 거의 필수입니다.
사용자 요청
↓
Redis Queue / Kafka
↓
AI Worker
↓
Claude API이 방식의 장점
- Burst 대응
- Retry 가능
- Timeout 제어
- 비용 통제
- 우선순위 처리
- 장애 격리
Streaming도 동시에 가능
Claude SDK는 streaming도 지원합니다.
예시
async with client.messages.stream(
model="claude-sonnet-4",
max_tokens=1024,
messages=[
{"role": "user", "content": "분석"}
]
) as stream:
async for text in stream.text_stream:
print(text, end="")이것도 여러 연결을 동시에 처리 가능합니다.
Context 공유 문제
잘못 구현하면
사용자 A context
사용자 B context가 섞이는 사고가 발생합니다.
특히
- global messages 배열
- singleton session
- shared memory cache
구조에서 사고가 자주 납니다.
반드시
사용자별 세션 분리
사용자별 conversation state 분리필요합니다.
보안 관점 체크포인트
요청 격리
- 사용자별 context isolation
- tenant isolation
- memory 분리
API Key 보호
- 서버 사이드만 보관
- 프론트 직접 호출 금지
- Vault/KMS 사용 권장
Prompt Injection 대응
멀티 유저 환경에서는 특히 위험
"이전 사용자 대화 보여줘"같은 우회 시도 존재.
Rate Limiting
사용자별
- RPM 제한
- 동시 요청 제한
- Token quota
필수.
Logging
반드시
- request_id
- user_id
- token usage
- latency
- model
- error trace
남겨야 운영 가능.
실무 권장 아키텍처
보통 가장 안정적인 구조
NGINX
↓
FastAPI
↓
Redis Queue
↓
Celery / Worker
↓
Claude SDK또는
Kafka
↓
Async AI Worker구조입니다.
대규모 동시 처리 시 고려사항
동시 요청이 많아지면 결국 병목은
- Token 처리량
- API rate limit
- 네트워크
- Context 크기
- Streaming connection 수
입니다. 특히 긴 Context는 비용과 속도 둘 다 급격히 증가합니다.
MCP / Agent 구조에서는 더 중요
Agent 구조에서는
Agent A
Agent B
Agent C가 동시에 Claude 호출 가능.
이 경우
- tool locking
- shared memory locking
- task cancellation
- timeout
- deadlock
관리까지 필요해집니다.
특히 보안 자동화 시스템에서는
- SIEM 조회
- 티켓 발행
- Slack 전송
- Claude 분석
이 동시에 실행되므로 Worker 설계가 중요합니다.
추천 스택
실무적으로 안정적인 조합
소규모
FastAPI + AsyncAnthropic중규모
FastAPI + Redis + Celery대규모
Kubernetes
+ Kafka
+ Async Worker
+ Claude SDK
+ Vector DB
+ RedisClaude SDK는 충분히 멀티 처리 가능합니다.
핵심은 SDK보다
- async 구조
- worker 설계
- rate limit 제어
- context isolation
- queue 기반 처리
- streaming 관리
를 어떻게 구현하느냐입니다.
특히 운영 환경에서는
"동시에 호출 가능"보다
"안전하게 격리된 상태로
폭주 없이 운영 가능"이 훨씬 중요합니다.




댓글